
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
GPT-4、Bard、Claude2などの異なる大規模言語モデル(LLM)が円卓を囲んで議論すると、より高精度な回答が得られることが研究報告されました。
このような「異種LLMs円卓会議」のアプローチは、各モデルの強みを活かし、弱点を補完することで、全体としての推論能力を向上させる可能性があります。
(さらに素晴らしいに、)この”異種LLMs円卓会議ツール”は公開されており、研究者や開発者が容易にこの手法を試すことができます。
この記事では、この興味深い研究とその実用ツールについて詳しく解説します。そして記事の最後には、Xで騒ぎになった「あの作品との類似性」についても考察します。
参照論文情報
- タイトル:ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs
- 著者:Justin Chih-Yao Chen, Swarnadeep Saha, Mohit Bansal
- 所属:University of North Carolina
- URL:https://doi.org/10.48550/arXiv.2309.13007
- GitHub:https://github.com/dinobby/ReConcile
「LLMエージェント」関連研究
- GPT-4などのLLMをエージェントとして既存ゲームシステムに導入し、NPCをAI化するツール『MindAgent』登場
- 多様な役割のAIエージェント達に協力してソフトウェアを開発してもらう『ChatDev』登場。論文内容&使い方を解説
- 大規模言語モデル同士に上手く協力してソフトウェア開発をしてもらうフレームワーク「MetaGPT」
従来の課題と背景
複雑な推論タスクの限界
大規模言語モデル(LLM)は、一般的な質問応答やテキスト生成タスクで優れた性能を発揮していますが、複雑な推論タスクにおいてはまだ十分な力を持っているとは言い難い現状があります。多段階の推論や複数の情報源を統合するような高度なタスクでは、特に単一のモデルでは限界があるとされています。
自己反省とフィードバックの課題
さらに、単一のLLMが自己反省やフィードバックを行う能力にも限界があると考えられています。モデルが自らの推論過程や結果に対して、十分な評価や修正を行えないためです。そして誤った推論がそのまま出力されたり、ハルシネーションが含まれるリスクがあります。
以上のような課題は、LLMがより広範な分野で機能する(高度な推論タスクに対応する)ための大きな障壁となっています。これに対する解決策が議論されています。
研究者らのアイデアと主要な成果
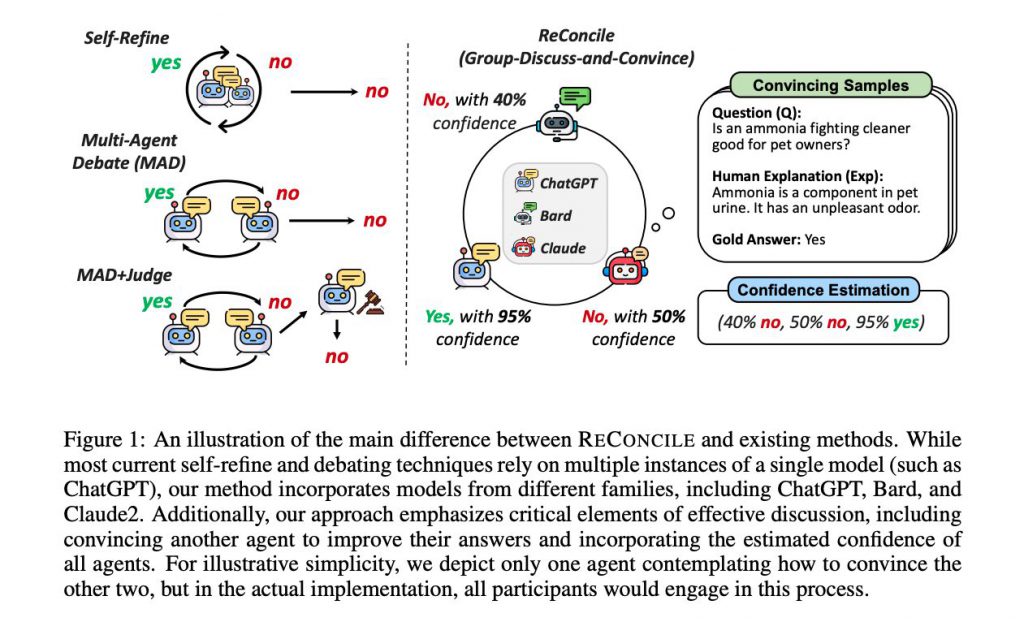
異種LLM同士の議論
米ノースカロライナ大学の研究者らは、異なる種類の大規模言語モデル(LLM)同士に議論させるというアプローチを採りました。
このアイデアの背後には、異なるモデルがそれぞれの強みと弱みを持っているという認識があります。例えば、GPT-4は一般的なテキスト生成に優れている一方で、Bardは物語生成に特化しています。これらのモデルを組み合わせることで、より高度な推論が可能になると考えられています。
研究者らは、複数の異なるLLM(GPT-4、Bard、Claude2など)を円卓会議のような形で議論させるアイデアを形にしました。各モデルは独自の視点と推論能力を持ち寄り、最終的な回答や結論を出す過程が検証されました。
異種LLMs円卓会議ツール
研究者らはただ実験を行って報告するだけでなく、LLM同士に議論させて答えを提出させるプロセスを自動化するツールも提供しています。このツールを使用することで、一般のユーザーも実際に異種LLM同士の議論を行わせることができます。
このツールの最大の利点は、複数のLLMを簡単に連携させることができる点です。複雑な問題に対して、各モデルの特長を活かした解決を試みることが可能になります。
LLM円卓会議のフレームワーク
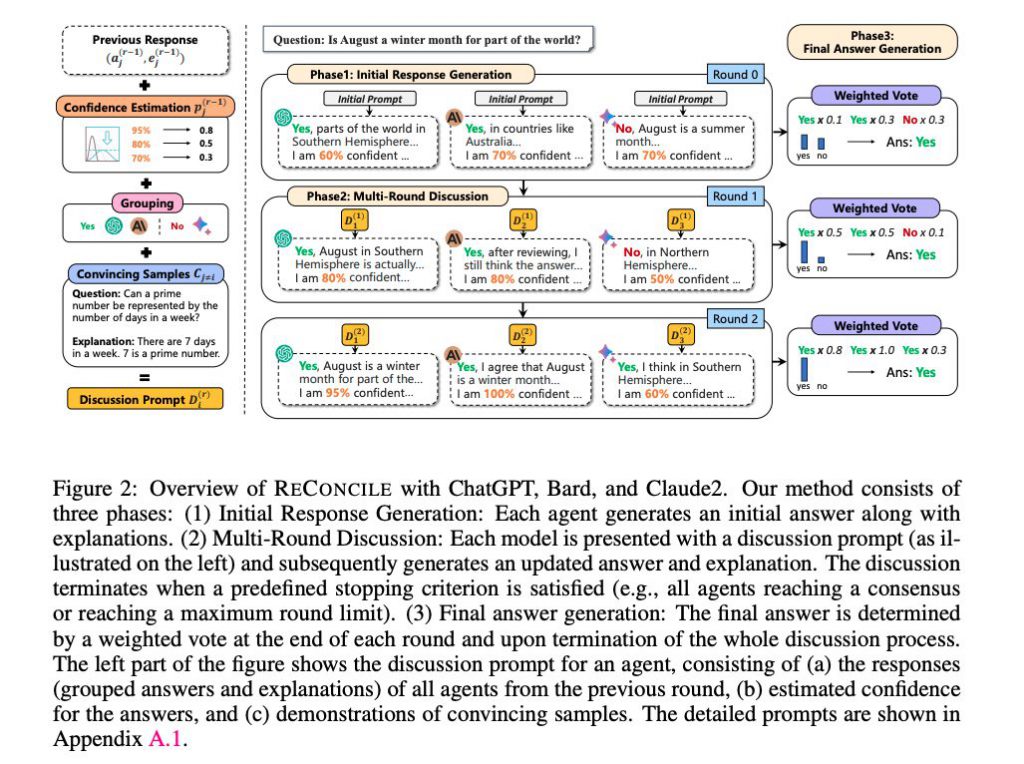
1. 初期回答と説明の生成
このフレームワークの最初のステップでは、複数の大規模言語モデル(LLM)が同時に参加します。そしてまず、GPT-4、Bard、Claude2などの異なるLLMが各々初めに回答と説明を生成します。この段階で各エージェント(LLM)は、問題に対する独自の視点と解釈を提供しています。つまり「意見がバラバラ」な状態です。
この初期生成の目的は、各エージェントが持っている独自の知識や推論能力を最大限に(あるいは自由に)発揮することです。このステップがあってこそ、後のステップで他のエージェントの回答と比較した際に、より多角的な視点が得られます。
2. 回答と説明の修正
次に、各エージェントは他のエージェントが生成した回答と説明を参考にして、自分自身の回答と説明を修正します。このプロセスは、各エージェントが他のエージェントの強みや弱みを理解し、それを自分の回答に反映させるためのものです。
この修正のプロセスでは、各エージェントは他のエージェントの回答に対する評価やフィードバックも考慮に入れます。各エージェントは自分の回答をより精緻に、そしてより正確にすることができます。
3. 最終回答の収束
最後に、全てのエージェントが同じ回答に収束した場合、その回答が最終的なものとされます。この収束は、各エージェントが持つ異なる視点と知識が統合され、最も確からしいと考えられる回答が導き出される結果です。
この収束が持つ意義は大きく、多角的な視点と多様な知識が一つの回答に統合されることで、その回答の信頼性と正確性が高まるとされています。
実験結果
ベースラインを上回る性能
研究者らは100のテーマで実験を行い、その結果、このLLM円卓会議フレームワークは既存の単一エージェントやマルチエージェントのベースラインを7.7%上回る性能を示しました。
ベースラインとは、既存の単一エージェントやマルチエージェントの平均的な性能を指します。この7.7%の向上は、フレームワークの有効性を強く示すものとなっています。
GPT-4のパフォーマンス向上
GPT-4に注目した場合、そのパフォーマンスが絶対値で10.0%向上したことが確認されました。
GPT-4は、現在最も広く使用されている大規模言語モデルの一つです。そのため、このモデルでの性能向上は、フレームワークの汎用性と有用性を示す重要な指標となります。
議論が進むにつれての精度向上
さらに、議論が進むにつれて各エージェントの精度が向上するという結果も得られました。
この現象は各エージェントが他のエージェントの回答と説明を参考にして自分の回答と説明を修正するプロセスによって生じています。エージェント間の協調と相互補完が効果的に行われ、最終的な回答の精度が高まっているという解釈ができます。

