
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
OpenAIが最近リリースしたGPT-4V(ビジョン)は、従来のChatGPTが持っていたテキスト処理能力に加え、画像分析機能を備えています。この進化において、GPT-4Vは「画像処理の安全性能」と「嗜好性の学習」が強化されています。また、DALL-E3との連携においても非常に有用であると期待されます。
なお、本技術によって実現される「見る」に加え、ChatGPTは「聞く」、「話す」ことができるようにもなります。(9/25より)2週間かけて、PlusユーザーはChatGPTに画像を見てもらったり音声で会話できるようになります(iOS & Android)。
本記事では、GPT-4Vの論文を参照して、従来の課題や今後出来るようになること、安全性への取り組みや視覚障害者支援機能などについて説明します。
参照論文情報
- タイトル:GPT-4V(ision) System Card
- 著者:OpenAI
- 所属:OpenAI
- URL:https://cdn.openai.com/papers/GPTV_System_Card.pdf
- 公式サイト:https://openai.com/research/gpt-4v-system-card
関連研究
- ChatGPTの”ふるまいの変化”を定量的に分析した結果
- OpenAI、大規模言語モデルの数学能力を大きく向上させることに成功
- GPT-4を使用した知的労働者のパフォーマンスは軒並み向上し、もとの成績が良くないほど顕著。※注意点あり
従来の課題
GPT-4Vは、従来のGPT-4が抱えていたいくつかの課題を解決する形で登場しました。
テキスト中心の処理能力
従来のGPT-4は、テキストデータの処理能力に特化しており、テキストベースの質問応答、文章生成、自然言語理解など、多くの用途で非常に有用でした。
しかし、裏を返せば画像や音声など他のメディア形式に対する対応が不足していました。テキストと画像が組み合わさったマルチモーダルなデータに対する処理能力が限定的でした。
画像入力とプライバシー
GPT-4の画像データに対する安全な処理能力には限界がありました。例えばプライバシー保護の観点がその一つです。
そのため、Advanced Analyticsやプラグインモードでの画像分析は非常に制限されていました。ユーザーがアップロードする画像データに含まれる個人情報やセンシティブな内容に対応できる技術が不足していたためです。


科学的・医学的な限界
GPT-4は、一般的な科学的な質問や医学的なアドバイスに対しても一定の回答能力を持っていました。しかし、その回答が不正確である場合、特に危険な化学物質や薬物に関する誤情報を提供する可能性があり、これが非常に危険な状況を引き起こす可能性がありました。
モデルの偏見と信頼性
AIモデルが持つ偏見や信頼性の問題は、業界全体でよく知られている課題です。GPT-4も例外ではなく、特に画像データを用いた場合、その偏見や信頼性の問題がさらに顕著になる可能性がありました。
GPT-4Vができること&特長
1. 画像入力の分析能力
GPT-4Vは、テキストだけでなく画像入力も分析できるという画期的な特長を持っています。この機能は、テキストと画像の両方に対応する多モーダルAIの新しい領域を拓くものと期待されています。GPT-4Vはユーザーが提供する画像を解析し、その内容に基づいてテキスト出力を生成することができます。この機能は、例えば医療画像の解析や視覚障害者へのサポートなど、多岐にわたる応用が考えられます。

2. 画像出力の不明点と可能性
現時点でGPT-4Vが画像を出力できるかどうかについては、公式な情報はありません。しかし、OpenAIが開発したDALL-Eなどの画像生成AIとの連携が将来的には考えられる(発表済み)ため、この点には注目が集まっています。
3. RLHF(人間フィードバック強化学習)による嗜好性の学習
GPT-4Vは、人間フィードバック強化学習(RLHF)という先進的な学習アルゴリズムを用いています。このアルゴリズムにより、モデルはユーザーが求める、または好む形の出力を生成するように設計されています。
この実装により、ユーザー体験が向上するだけでなく、AI活用の倫理的な側面も進歩すると考えられます。ユーザーの生活を豊かにするというテクノロジーの基本理念に沿って、偏見を減らし、透明性と安全性を向上するものだと期待されるためです。
4. Be My Eyesとの連携による視覚障害者支援
最も注目すべき特長の一つが、視覚障害者支援アプリ「Be My Eyes」との連携です。この連携により、「Be My AI」という新しい機能が開発されました。この機能は、視覚障害者がスマートフォンで撮影した写真をGPT-4Vが解析し、その内容をテキストで説明するというものです。視覚障害者は周囲の環境や物の位置、食品のラベルなどを理解する手助けを受けることができます。
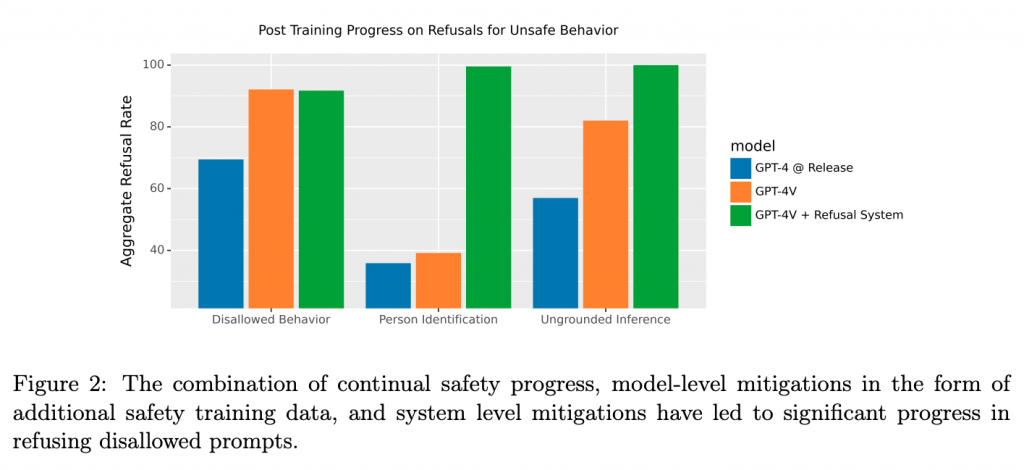
安全性について
OpenAIによる内部評価
GPT-4Vの安全性は、OpenAIの内部評価プロセスによって厳密に評価されています。この評価によって、テキストコンテンツに対する既存のポリシーに対する拒否のパフォーマンスが、GPT-4Vの基本言語モデルと同等であることが示されています。さらにシステムレベルでは、既存のモデレーション分類器が、事後の監視と施行のパイプラインに情報を提供しています。
外部専門家による評価
OpenAIは、外部の専門家と協力して、モデルとシステムに関連する制限とリスクを定性的に評価しています。この「レッドチーミング」は、特にGPT-4Vの多モーダル(ビジョン)機能に関連するリスクをテストするために設計されています。
なおレッドチーミングとは、組織のセキュリティ対策や戦略を外部の視点で評価・テストする手法です。専門の「レッドチーム」が敵役となり、実際の攻撃を模倣して組織の弱点を探ります。これにより、組織は自身の脆弱性を理解し、改善策を講じることができます。
リスク要素
GPT-4Vは、特定の高リスク領域、例えば医学や科学的専門性において、モデルの能力が飛躍的に向上している場合があります。人々の画像に関連するリスク、例えば人物の識別や、人々の画像から生じる損害を減らすことができるとされています。
安全対策と緩和策
GPT-4Vは、GPT-4とDALL-Eで展開されているモデルレベルとシステムレベルの安全策からいくつかの優れた実装を受け継いでいます。テキストまたは画像コンテンツが単独で無害である場合でも、組み合わせて有害なプロンプトまたは生成を作成するような新しいリスクに焦点を当てることができます。

完全な安全性はまだ達成されていない
しかし重要な点として、エラーや偏見、プライバシー侵害を含む生成を行うリスクは、まだゼロではありません。OpenAIは、リアルワールドでの使用から学びながら、時間をかけて改善していく予定です。


