
かんたん読み上げ
ブラウザ内蔵・無料
0%
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
大規模言語モデル(LLM)の分野では、その推論能力が日々向上しています。本記事では、最新の研究「Better Zero-Shot Reasoning with Role-Play Prompting」を紹介し、ロールプレイプロンプティングがLLMの推論能力をどのように向上させるのかを探ります。
参照論文情報
- タイトル:Better Zero-Shot Reasoning with Role-Play Prompting
- 著者:Aobo Kong et al.
- 所属:レノボなど
- URL:https://arxiv.org/abs/2308.07702
関連研究
ロールプレイとは
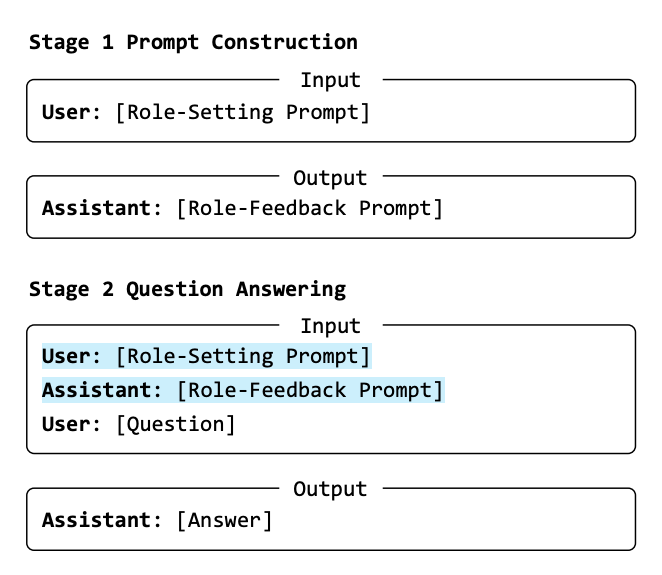
ロールプレイプロンプティングは、大規模言語モデル(LLM)に対して特定の役割を割り当て、その役割に基づいて推論を行わせる手法です。このセクションでは、ロールプレイプロンプティングの具体的なプロセスと、その背後にある理論的な考え方を詳細に解説します。
役割の割り当て
ロールプレイプロンプティングでは、最初にモデルに特定の役割を割り当てます。この役割は、モデルが推論を行う際の視点や態度を形成します。
例:
- ユーザー: 「あなたは数学の教授です。」
- モデル: 「数学の教授として、微分方程式について教えることができます。」

ロールフィードバック
次に、モデルが割り当てられた役割に忠実な応答を生成するためのフィードバック段階があります。この段階での対話は、モデルが割り当てられた役割に対してより具体的な視点を持つことを助けます。
例:
- ユーザー: 「今日の講義では微分方程式について教えています。」
- モデル: 「微分方程式は数学の基本的な概念で、物理学、工学、経済学など多岐にわたる分野で使用されます。今日の講義では、一階および二階の微分方程式の解法に焦点を当てます。」
役割の浸透
ロールプレイプロンプティングの成功は、モデルが割り当てられた役割を完全に理解し、その役割に基づいて一貫した推論を行う能力にかかっています。役割の浸透を確保するためには、モデルのロール認識に対して訂正が必要な場合の対処法も考慮する必要があります。
ロールプレイ状態のLLMの性能
ロールプレイプロンプティングがLLMの性能にどのような影響を及ぼすのかを理解するために、論文で報告されている実験内容を紹介します。

