ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
これまでの大規模言語モデルは基本的にテキストデータのみを扱うことが前提でした。Metaとケンブリッジ大学の研究者チームは、この限界を打破する新たな手法を提案しました。
参照論文情報
- タイトル:Prompting Large Language Models with Speech Recognition Abilities
- 著者:Yassir Fathullah, Chunyang Wu et al.
- 所属:Meta AI、ケンブリッジ大学
- URL:https://doi.org/10.48550/arXiv.2307.11795

関連研究
音声データを直接理解するAI
研究の目的と手法
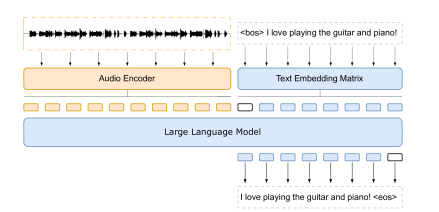
この研究の主要な目的は、大規模言語モデルが音声データを直接理解し、それに対応する形で反応する能力を付与することです。従来のAIは、音声データをテキストデータに変換することで理解していました。しかし、この研究では新たなアプローチを採用し、音声データとその対応するテキストデータを訓練データに組み込むことで、大規模言語モデルが音声データをテキストデータに変換することなく、直接音声データを理解する能力を付与します。
音声データの取り扱い
これまでの大規模言語モデルはテキストデータのみを扱うことが前提でしたが、この研究により、音声データを直接扱うことが可能になりました。これは、AIが人間の音声をより直接的に、より高精度に理解する新たな局面を開くことを意味します。
音声データの直接的な理解は、AIの応用範囲を大幅に広げる可能性があります。例えば、音声を直接理解することで、音声のニュアンスや感情をより正確に捉えることが可能となり、より自然な対話を実現することが期待できます。また、音声データの直接的な理解は、音声認識の誤りを減らすことにも寄与する可能性があります。
中間ステップを飛ばす
音声とテキストの直接的な関連性
この研究の中心的な技術は、音声とテキストの間に直接的な関連性を構築することです。これまでの一般的な手法では、音声をテキストに変換するために、音声認識(ASR)という中間ステップが必要でした。しかし、この新しいアプローチでは、ASRを介さずに音声から直接情報を抽出することが可能になります。これにより、音声データの理解と処理がより効率的かつ精密に行えるようになります。
データの前処理と学習
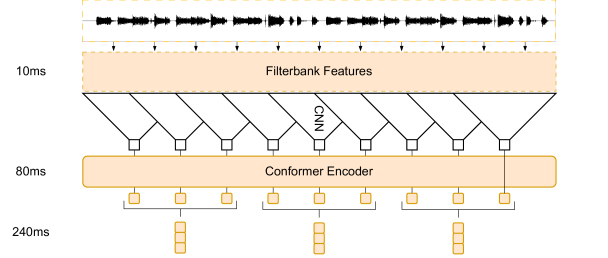
この技術では、音声データを大規模言語モデルが理解できる形に前処理します。具体的には、音声データをメルスペクトログラムに変換し、その後、トークン化します。これにより、音声データが言語モデルにとって扱いやすい形になります。そして、この前処理されたデータを用いて、言語モデルは学習を行います。