
本記事では、コード生成に特化したLLM「Qwen2.5-Coder」の研究成果を紹介します。
このモデルは、GPT-4oやClaude3.5に匹敵する性能を持つオープンソースのコードLLMとして注目を集めており、0.5Bから32Bまでの6つのサイズ展開で、40以上のプログラミング言語に対応しています。
5.5兆トークンという膨大なデータでの学習で、コード生成・デバッグ・SQL生成など多岐にわたる機能を備え、開発者の実用的なニーズに応えることを目指して開発されました。

参照文献情報
- タイトル:Qwen2.5-Coder Technical Report
- 著者:Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, Junyang Lin
- 所属:Qwen Team of Alibaba Group
背景
プログラミングに特化した言語モデルの研究が活発に行われています。これまでStarCoderシリーズ、CodeLlamaシリーズ、DeepSeek-Coderシリーズ、CodeQwen1.5、CodeStralなど、多くのコードLLMが開発されてきました。
しかし、最新の非公開モデルであるClaude-3.5-SonnetやGPT-4oと比べると、オープンソースのコードLLMには、まだ改善の余地がありました。
このような背景から、今回研究チームは以前開発したCodeQwen1.5の経験を生かし、より性能の高い新しいモデルの開発に取り組むことにしました。5.5兆を超える大量のデータを用いて、プログラミングに特化した事前学習を行うことにしたのです。
データの収集には、GitHubなどのプログラミング関連サイトやウェブから得られた情報を活用したそうです。ただし、単にデータを集めるだけでなく、質の低いコンテンツを取り除くため、機械学習を使った選別も行っています。
さらに、プログラミングだけでなく、数学や一般的な文章の理解力を持つことも目指しています。そのため、コード、数学、一般テキストをバランスよく組み合わせてデータが作成されました。
そして0.5Bから32Bまでの異なる規模のモデルを開発することで、様々な用途に対応できるようにしています。
このように、既存のコードLLMの限界を超え、より使いやすく高性能なモデルを作ることが、本研究の出発点となっています。実際の開発現場での活用を強く意識し、コードアシスタントやプログラム関連のツールとして実用的なモデルを目指していることが特徴です。
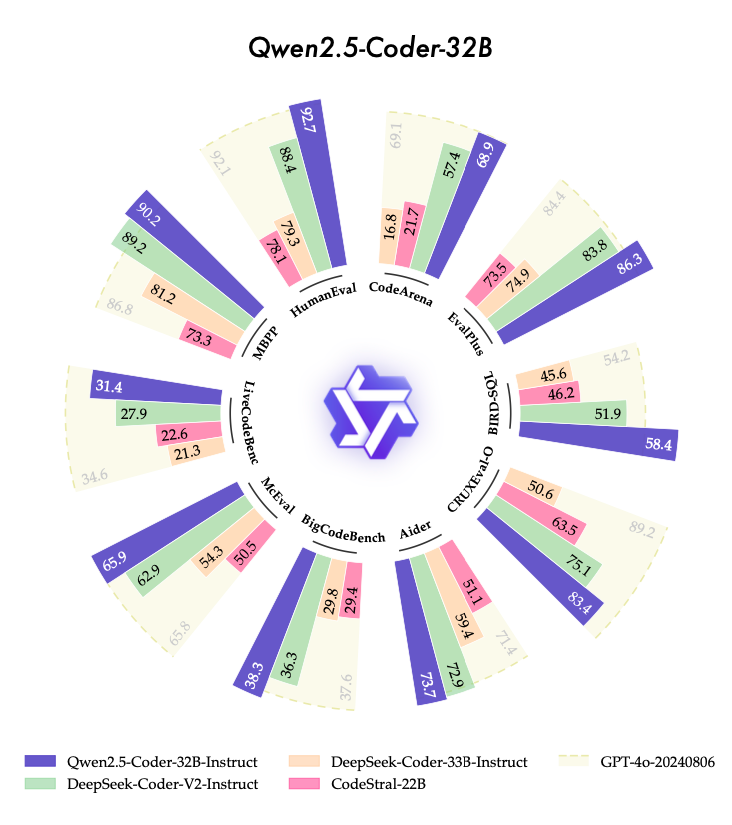
以下で本モデルの構造やいかに優れているかといった実験結果をまとめて紹介します。

