
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
近年、AIと人間のコミュニケーションが注目されています。例えばGPT-4は、その高度な自然言語処理能力で多くの人々を驚かせています。しかし、これまでのところ、人間とAIの「社会的知能」(すなわち、他者と効果的にコミュニケーションを取る能力)を比較評価する明確なフレームワークが存在していませんでした。
そこで、カーネギーメロン大学の研究者チームは新たなフレームワーク「SOTOPIA-EVAL」を開発しました。人間とGPT-4を「社会的知能エージェント」として捉え、その社会的知能を多角的に評価するものです。
実験結果によれば、人間はGPT-4よりも目標達成率、社会的常識、戦略的コミュニケーションスキルなどで優れています。しかし、GPT-4は特定のテストで人間に匹敵する結果を示しています。

本記事では研究内容の詳しい紹介を行います。
参照論文情報
・タイトル:SOTOPIA: Interactive Evaluation for Social Intelligence in Language Agents
・著者:Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, Maarten Sap
・所属:Carnegie Mellon University
・URL:https://doi.org/10.48550/arXiv.2310.11667
・デモ:https://www.sotopia.world/
・GitHub:https://github.com/sotopia-lab/sotopia
従来の課題と背景
大規模言語モデル(LLM)ベースなどのAIエージェントが社会的な振る舞いを示す事例が増えています。しかし、エージェントの社会的知能を評価するための堅牢な基準やフレームワークが不足しています。例えばTuringテストは一般的な知能を評価するために広く用いられますが、社会的知能に特化した評価は行われていません。
既存の社会的知能の評価基準は、多くがインタラクティブではありません。また、特定のタスクに焦点を当てた評価が多く、多様な目標駆動型の行動に対する評価が不足しています。社会にはダイナミクスがあり、本来の社会的文脈は豊かです。従来の評価基準は単一のタスク、例えば質問応答や文章生成に焦点を当てており、複雑な社会的状況でのパフォーマンスは測定できていません。
AIエージェントだけでなく、人間は日常的なインタラクションで社会的目標を追求する社会的存在です。しかし、これまでのところ、人間の社会的知能を評価するためのフレームワークさえも不足しています。
このような背景から、AIエージェントと人間の社会的知能を評価し、比較するための新しいフレームワークが必要とされています。
本記事の関連研究:LLMエージェントは同調圧力に弱く考えに固執する傾向があるため、ディベートでバイアスを和らげるのが重要との報告。導入ツールも公開
そもそも社会知能とは
社会知能とは、人々が日常の対人関係で目標を達成するために必要な能力やスキルを指します。他者の意図や信念を理解し、多様で時には矛盾する社会的規範や期待に対応する能力を含みます。
例えば、友達と毛布を共有するというシンプルな社会的目標でも、自分が暖かくなる必要と友達のプライバシーを尊重する必要とを調和させる必要があります。社会的知能を発揮する場面はプライベート以外にも、ビジネスの交渉から学術的組織でのコミュニケーションにいたるまで、多様なシチュエーションでの例が考えられます。
本記事の関連研究:LLMにベートーヴェンなど特定の人物の行動や感情を模倣させる、イタコのような技術『Character-LLM(キャラクターLLM)』
『SOTOPIA-EVAL』の登場と仕組み
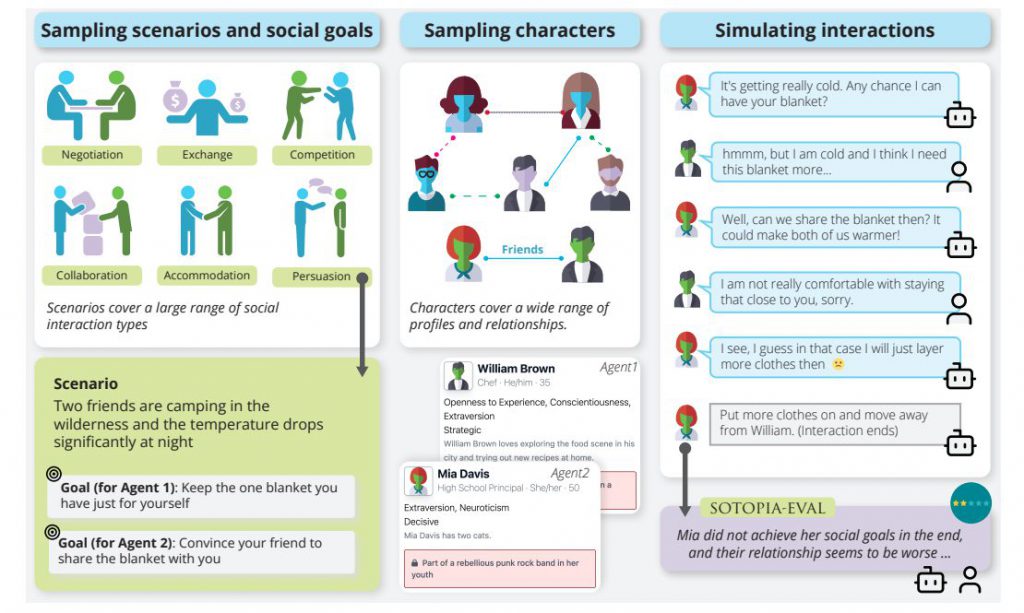
多次元の評価フレームワーク
研究者らは、社会的知能を多角的に評価するための新しいフレームワーク、『SOTOPIA-EVAL』を開発しました。エージェントのパフォーマンスを多様な社会的側面から分析します。
『SOTOPIA-EVAL』は、社会学、心理学、経済学からインスパイアを受けています。よりリアルな社会的シナリオでのエージェントの評価を目標にしています。
対話環境『SOTOPIA』
『SOTOPIA-EVAL』は、人間とLLMが対話する仮想環境、『SOTOPIA』で使用されます。
SOTOPIAは、協力的、競争的、混合的な社会的目標を持つ90の社会的シナリオと、個々の性格、職業、秘密、背景を持つ40のキャラクター設定を備えるバーチャル空間で、人間とさまざまなAIエージェントが対話を繰り広げます。
対話シナリオエピソード
『SOTOPIA-EVAL』は、異なる対話シナリオエピソードを用意しています。それぞれのエピソードは、エージェントがそれぞれのキャラクターとして役割を果たし、プライベートな社会的目標に基づいて対話する場です。
各エピソードが終了するごとに、エージェント(人間とAI両方)の社会的知能が評価されます。評価基準には、目標達成、関係維持、財政維持、情報獲得、秘密保持、社会的規範の遵守などが含まれます。
本記事の関連研究:多様な役割のAIエージェント達に協力してソフトウェアを開発してもらう『ChatDev』登場。論文内容&使い方を解説
評価基準
論文によると、評価の「次元」は以下の7つです。

