
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
マンチェスター大学などの研究者によって、SNSのテキストから精神状態を高い精度で解析することができるオープンソースの大規模言語モデル(LLM)『MentalLLaMA(メンタルラマ)』が開発されました。
精神的な健康問題の解決は、世界的な課題です。しかし、多くの患者は、社会的な偏見などの理由で適切な精神医療を受けることがありません。
ソーシャルメディアは、人々の日常生活に不可欠なものとなっています。特に精神的に不安定な状態にある人々は、Xなどのプラットフォームで自分の感情やストレスを共有する傾向があります。
現時点ではSNSの投稿をどのような目的で分析に活用するのか制限がある場合もありますが、技術的な検証は多くの可能性を拓くものになるのは間違いありません。
参照論文情報
- タイトル:MentalLLaMA: Interpretable Mental Health Analysis on Social Media with Large Language Models
- 著者:Kailai Yang, Tianlin Zhang, Ziyan Kuang, Qianqian Xie, Sophia Ananiadou
- 所属:The University of Manchester, Jiangxi Normal University
- URL:https://doi.org/10.48550/arXiv.2309.13567
- GitHub:https://github.com/SteveKGYang/MentalLLaMA
心や性格に関する関連研究
- ポーカーなど不完全情報ゲームを「心の理論」で上手にプレイするGPT-4ベースの『Suspicion(疑心)-Agent』松尾研など開発
- 「心の理論」においてGPT-3は人間の3歳、GPT-4は人間の7歳(基本の概念を理解しているレベル)に相当するとの研究報告
- LLMの個別の性格(人格)特性を、プロンプトで「測定」「形成」する手法
従来の課題
精度の問題
SNSの投稿からメンタルヘルスを分析する研究は数多く行われてきました。しかし、これまでの手法では精度が高いとは言えませんでした。従来は、自然言語処理(NLP)技術を用いた「テキスト分類タスク」としてメンタルヘルス分析を行ってきました。これらの手法は、その解釈性が低いという問題がありました。ブラックボックスとも呼ばれます。
解釈性の欠如
解釈性が低いということは、その分析結果がどのように導き出されたのか、何を基にしているのかが不明確であることを意味します。
この問題は他の課題よりも診断や治療においては非常に重大です。診断の中でもメンタルヘルスでは、単なる数値やラベルよりもその背後にある要因や状態を理解することが重要なのでより難しいアプローチとなっていました。
データの品質
また、NLP手法は高品質なトレーニングデータを必要としますが、メンタルヘルス分析においては、詳細かつ信頼性のある説明を提供するオープンソースのデータが不足しています。研究トピックがセンシティブであり、ドメイン専門家による説明の作成コストが高いためです。
資源の制限
さらに、解釈可能なメンタルヘルス分析のためのLLM(Large Language Models)の微調整には、高いコストがかかる場合があります。これは、関連する研究コミュニティの発展を妨げる要因ともなっています。
以上のような問題点を解決するためには、新しいアプローチが求められています。
研究者らの主なアイデア
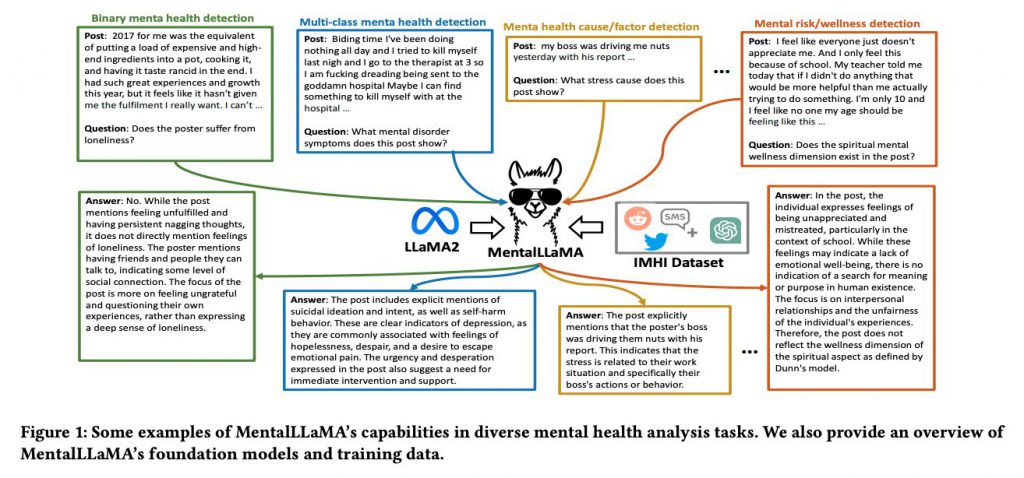
研究者らの主なアイデアは、高品質な特化データでLLMを訓練することで、SNSの投稿からのメンタルヘルス分析の精度を向上させるというものでした。
研究者らは、従来の問題に対処するために、LLMを高品質な特化データで訓練する新しいアプローチを採用しました。そして、新しいモデル『MentalLLaMA』の設計と訓練にたどり着きました。またMentalLLaMAモデル訓練には独自のデータセットが用いられました。

MentalLLaMAのレシピ
MentalLLaMAのレシピは、多様なSNSからのデータ収集、ChatGPTによる説明の生成と評価、そしてLLaMA2を用いた訓練というステップから成り立っています。これにより、高精度なメンタルヘルス分析が可能なMentalLLaMAが完成しました。
IMHIデータセットの構築
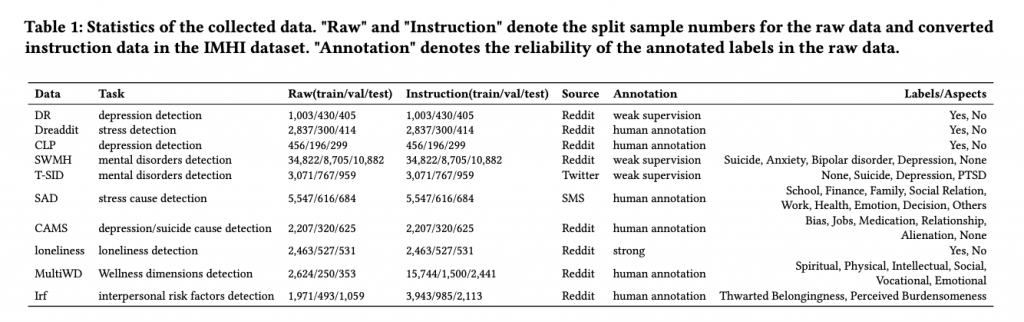
研究者らは、まず最初にInterpretable Mental Health Instruction(IMHI)という名前の新しいデータセットを構築しました。
このデータセットは、105Kのデータサンプルを含み、多くの異なるメンタルヘルス関連のタスクに対応しています。データは、Reddit、Twitter(X)、SMSなど、複数のソーシャルメディアプラットフォームから収集されました。
データの説明付与
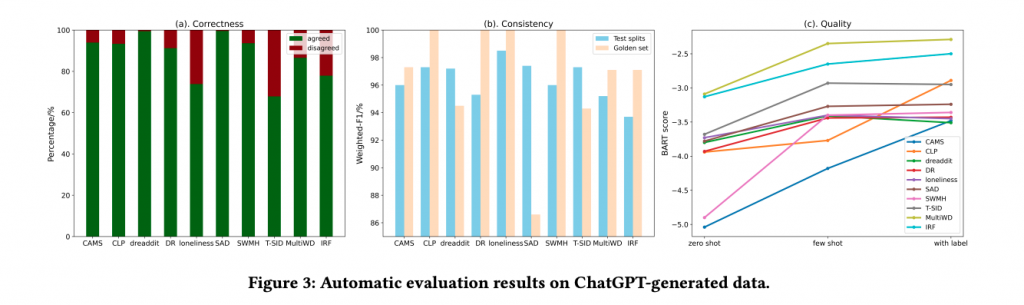
収集されたデータには、ChatGPTを用いて説明が付与されました。この説明は、データがどのようなコンテキストで生成されたのか、何を意味しているのかを明示するものです。
説明の評価
ChatGPTによって生成された説明は、AIGC(AI Generated Content)評価によって評価されました。この評価により、説明の質が確保され、訓練データの信頼性が向上しました。
モデルの訓練
上記で収集され、説明と評価が付与された「データ+説明」を用いて、LLaMA2モデルが訓練されました。この訓練によって、MentalLLaMAが完成しました。
性能評価実験と結果
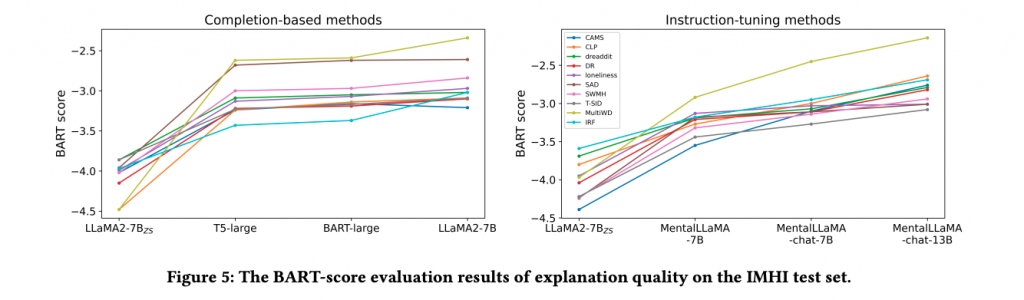
MentalLLaMAの性能は、厳格な実験設計に基づいて評価されました。このセクションでは、その詳細と結果について解説します。
MentalLLaMAの性能評価には、メンタルヘルス分析のための特定のベンチマークが用いられました。このベンチマークには、複数のタスクとテストセットが含まれています。
タスクの詳細
論文には4つの主要なタスクが明示されています:

