
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
近年、画像セグメンテーション技術は、その発展に伴いさまざまな分野で活用されています(そもそもセグメンテーションとは何か?については最初のセクションで紹介します)。一方で、従来の手法では柔軟性に限界がありました。本記事では、新たな画像セグメンテーション技術「SEEM(Segment Everything Everywhere All at Once)」について、その特徴や応用事例を紹介します。

セクション数が多く長い記事に思えますが、工夫を凝らして読みやすくしていますので、ぜひお気軽にご覧ください。
そもそもセグメンテーションとは
セグメンテーションとは、画像処理やコンピュータビジョンの分野で用いられる技術であり、画像内の各ピクセルに対して、それが属する物体やクラスにラベルを割り当てることを目的としています。要するに、「画像の中に何が写っているか」を認識するテクノロジーです。セグメンテーションは画像からの情報抽出や解析が容易に行えるため、さまざまなアプリケーションで利用されています。
セグメンテーションには、主に以下の2つのタイプがあります。
- セマンティックセグメンテーション:
セマンティックセグメンテーションでは、画像内の各ピクセルに対して、所属する物体クラス(例:人、犬、車)のラベルが割り当てられます。このタイプのセグメンテーションでは、同じクラスの物体が複数存在する場合でも、それらは区別されずに同一のラベルが割り当てられます。 - インスタンスセグメンテーション:
インスタンスセグメンテーションでは、画像内の各ピクセルに対して、所属する個別の物体インスタンス(例:人1、人2、犬1)のラベルが割り当てられます。このタイプのセグメンテーションでは、同じクラスの物体が複数存在する場合でも、それぞれ異なるラベルが割り当てられます。
セグメンテーション技術は、過去数十年間で大きく進化しました。古典的な画像処理手法から始まり、近年ではディープラーニングを利用した手法が主流となっています。ディープラーニングを用いたセグメンテーション手法は、高い精度で物体の境界を検出することができるため、自動運転、医療画像解析、ロボティクス、ビデオ編集など、幅広い分野で活用されています。
SEEMの概要
今回新たにMicrosoftが発表した「SEEM」は、さまざまなタイプのプロンプト(クリック、ボックス、ポリゴン、スクリブル、テキスト、参照画像など)を用いて、一つのモデルで画像セグメンテーションを行うことができる技術です。この技術は、大規模言語モデル(LLM)にインスパイアされた、ユニバーサルでインタラクティブなマルチモーダルインターフェイスを提供します。
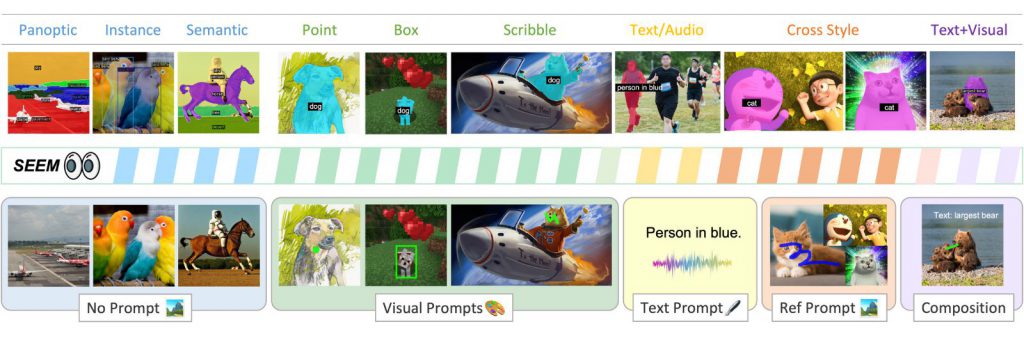
SEEMの特徴
SEEMは以下の4つの特徴を持っています。

