
どんなポーズも
「ポーズ」の検出は現在画像認識の分野で話題になっています。例えば、深層学習を用いて人物のポーズを可視化してくれるOpenPoseがあります。このほかにも、人物をポーズ画像の動きに変換するモーション転送のタスクでは、様々なモデルが構築されています。
この分野の課題点として、対象者の顔が維持されなかったり、ポーズが上手く転送されなかったりします。さらに、どのような人物の画像でもいいというわけではなく、直立していない人に対しては、変換が上手くいかない場合が多いです。

モーション転送のタスクにおける体型や顔が維持できないという課題において、実際にどのような研究が行われているのでしょうか。FacebookのOran Gafniら研究者の発表を紹介します。
研究者らは、畳み込みニューラルネットワーク(CNN)を主に用いて、ネットワークを構築を試みました。
▼論文情報
著者:Oran Gafni, Oron Ashual, Lior Wolf
タイトル:”Single-Shot Freestyle Dance Reenactment”
Facebook
URL:DOI
1枚の画像でのポーズ画像の再現
まずはOran Gafniらの研究におけるミッション・手法・結果をまとめました。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから説明していきます。
ポーズ画像から人物画像にポーズを転送
目的は1枚の人物の入力画像で、ポーズ画像の動作を模倣することです。対象者は、体型・年齢・性別・ポーズや視点が全く異なっています。また、背景画像も人によって違います。このような厳しい制約下でモデルを構築することが目的となっています。
下図はポーズ再現の概略です。まず、対象者の画像とポーズ画像を用意します。そして、構築したモデルに入力すると、出力として対象者がポーズ画像のポーズに変換されます。同時に、体型・顔・背景も維持されていることが分かります。

CNNベースのネットワークを複数構築
Oran Gafniらは、CNNをベースとしたモデルを構築しました。
モデルは、独立して訓練された3つのネットワークにより構成されています。
- P2B(Pose-to-Body): ポーズと人物の情報をデータ化
- B2F(Body-to-Frame): 人間の身体をマッピング
- FR: 1, 2で生成されたフレーム内の顔を最適化
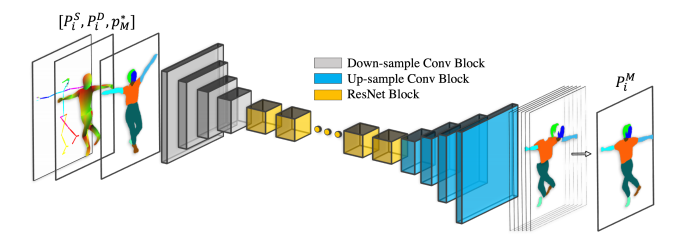
下図はP2Bネットワークの概略を示しています。目的は、ポーズを捉えて、身体の情報をデータ化することが目的です。入力としてポーズ画像が与えられます。ダウンサンプリング(灰色)部分はReLUが用いられたCNNです。そして、中間(黄色)にResNetが用いられており、アップサンプリング(青色)部分でも同じくReLUが用いられています。
P2BはVideo instance-level Parsing(VIP)データセットを用いて訓練されています。この中には、様々なポーズを取った人の画像とラベル付けがされています。
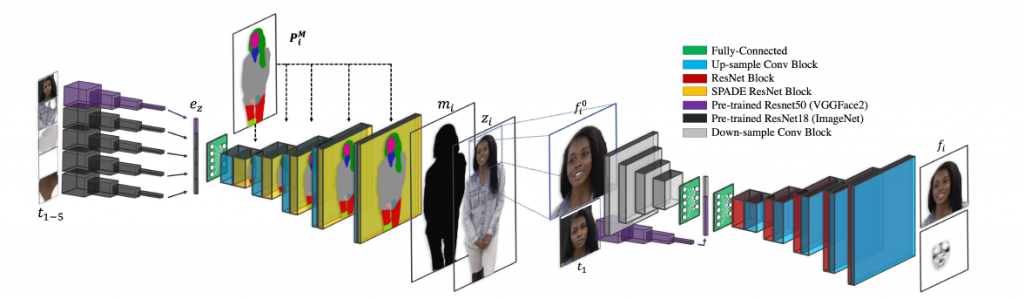
下図はB2FとFRネットワークのアーキテクチャです。このネットワークには5つの入力画像があり、体のパーツが部分的に切り取られています。例えば、髪と顔・上半身の衣服・肌の色などです。P2Bにより出力されたポーズ画像と合わせ、対象人物のポーズを作り出します。FRネットワークでは、顔を抽出して位置を合わせます。
B2Fの訓練には2つのデータセットが組み合わされています。これは、年齢や性別・民族などの様々な人物に対して変換を実現するために、堅牢性を向上させることを目的としています。1つはMHPv2で、251枚あたり平均3人のが写り込んでいます。もう1つはCIHPで、28,000枚の画像が含まれます。
複数の人物画像でポーズ転送に成功
結果、既存手法と比較して、直立している写真と様々な写真の両方で、良い生成結果が得られました。
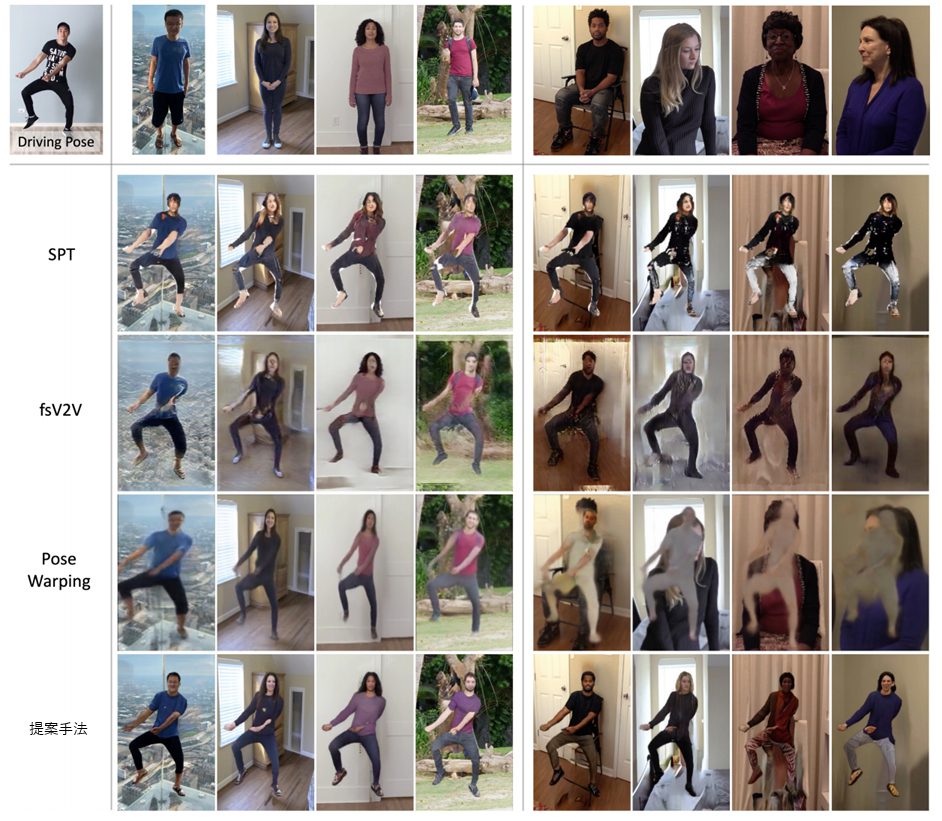
下図は、既存手法と提案手法との比較です。変換するポーズは左上にあり、左側の対象者は基本的に直立であり、右側の対象者はかなり異なったポーズをしています。これらの写真を左上のポーズに変換することが目的です。結果、両方の場合において、提案手法のほうが上手く処理できていることが分かります。
例えば、SPTは髪の毛や服装がかなり乱れており、左側においてもうまく生成できていないことが分かります。右側においては、うまくポーズはとれていますが、元の人物の原型をとどめていないことが分かります。対して提案手法は、服の色や顔などをかなり忠実に再現しています。
下図は既存手法と提案手法の評価です。直立でない、異なったポーズをとっている「挑戦的」なデータセットにおいては、既存手法はかなり苦戦しているため、単純な画像のみでのパフォーマンスを測定しています。結果としては、すべての指標において提案手法が上回っています。人間による評価では、提案手法と比較して、結果を好んだ割合が示されています。例えば、0.98であれば、98%の画像において、提案手法が評価されたということになります。

以下の写真は様々なポーズとその生成例です。かなり正確に再現できていますね。

研究紹介は以上です。ポーズの検出がより正確になることによって、画像認識分野がますます発展していくと良いですね。
関連記事
[blogcard url=”https://aiboom.net/archives/33049″]
[blogcard url=”https://aiboom.net/archives/47251″]
[blogcard url=”https://aiboom.net/archives/48815″]
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP