
■お知らせ:AIDBの感想を募集しています!
Gemini Pro 対 GPT-4V、画像認識能力でどちらが優秀なのか
GPT-4Vに対してGeminiの画像認識能力はどれほど性能が高いのか、さまざまなタスクで比較した実験結果が報告されました。
非常に多岐にわたるケーススタディを行った結果、両者の特性の違いが浮き彫りになってきています。
Geminiは画像とテキストの情報を統合する能力に長けているとのことです。

参照論文情報
- タイトル:A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
- 著者:Chaoyou Fu et al.(多数)
- 所属:Tencent Youtu Lab, Xiamen University, ECNU, USTC, Peking University, Shanghai AI Laboratory
- URL:https://doi.org/10.48550/arXiv.2312.12436
- GitHub:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
研究の背景
近年、人間のように複雑な情報を処理できるマルチモーダルAIの開発が進んでいます。マルチモーダルAIとは、異なる種類のデータ(例えばテキスト、画像、音声など)を理解し、組み合わせて処理するAIのことです。
現在、マルチモーダルAIの最先端としてGPT-4Vの存在があります。GPT-4Vは、言語と視覚情報を組み合わせたタスクで高いパフォーマンスを示すことで知られているモデルです。
本記事の関連研究:OpenAI、ChatGPTが画像を分析する『GPT-4V(ビジョン)』を発表。安全性、嗜好性、福祉機能を強化
一方、GPT-4Vに比肩する性能を持つとされる新たな多モーダルAIモデルGeminiが登場したことにより、どちらの性能が高いのか注目されるようになりました。
本記事の関連研究:Googleが「人間の専門家レベルを超える最初のモデル」とする『Gemini』発表、GPT-4を凌駕
そこでテンセントなどの研究者らは、GPT-4VとGeminiの能力を客観的に評価し、それぞれのモデルの特性を理解することで、より洗練されたAIの開発に繋げようと考えました。なお、GPT-4VとGeminiに加えてSPHINXというマルチモーダルモデルも一緒に検証されています。
AIの基本的な認識能力
まずはモデルがデータをどのように処理し、理解するかの基本が確かめられました。
物体中心の認識
物体の空間位置関係やオブジェクトを数えたりなどの基本的なタスクがあります。しかしモデルは左右の概念など、単純な空間的方向性を理解することに苦労していることが示されています。
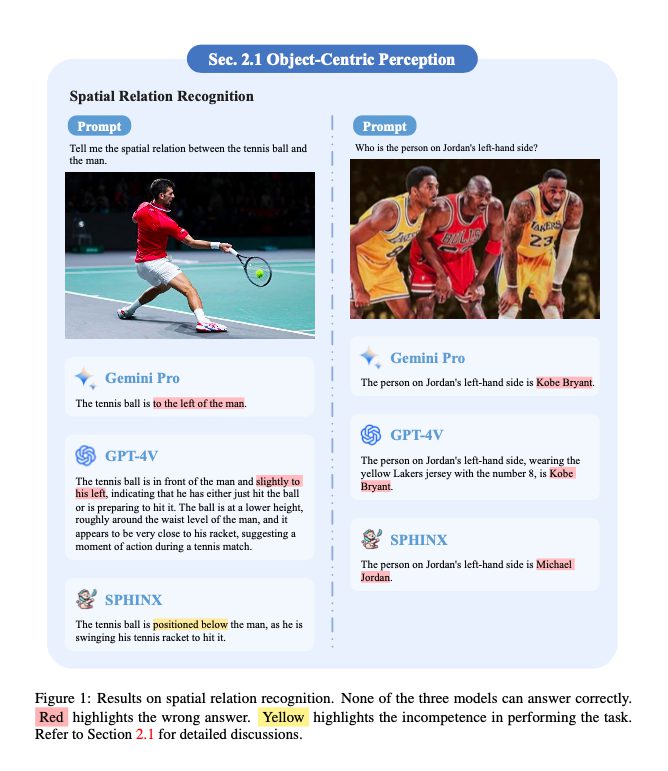
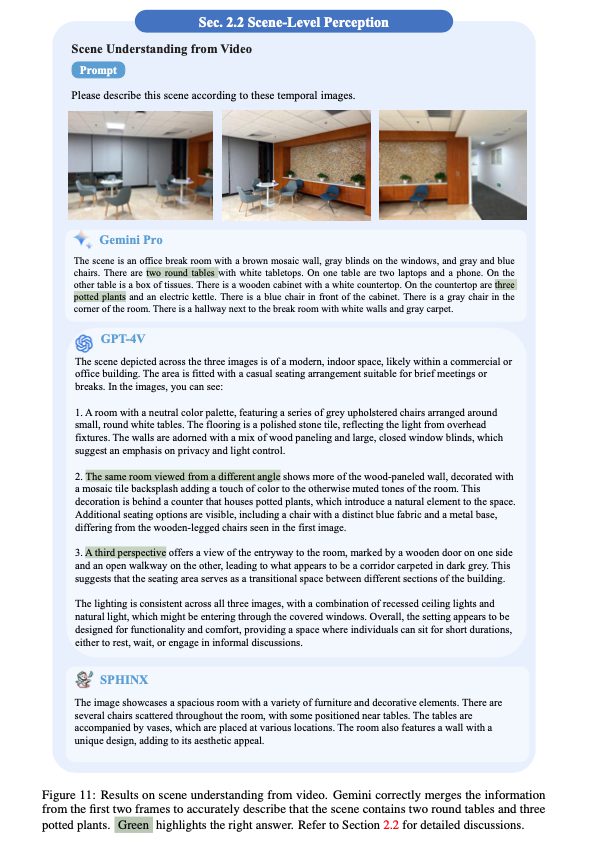
シーンレベルの認識
シーン全体を見る場合は、モデルは視覚的要素を可能な限り詳細に説明するように求められます。GPT-4Vは要素が密集している環境でも優れた性能を示しています。一方でビデオシーンの理解もテストされ、Geminiは異なるフレームからの情報を統合する能力を見せています。

視覚を超えた理解
なお、モデルは視覚があるだけでなく知識もあります。社会規範や物理法則に共通感覚を適用することで、見たものを理解する能力が高いのです。



本記事の関連研究:画像分析機能を持つオープンソースLLM『LLaVA-1.5』登場。手持ちの画像を分析可能。GPT-4Vとの違い
発展的な認知能力
テキストが多く含まれるコンテンツ
Gemini、GPT-4V、そしてSPHINXはフローチャートの理解や表の解析において異なるアプローチを示しました。Geminiは高レベルのアイデアを簡潔に要約する能力に長けており、GPT-4Vは詳細な説明を提供します(が、ときどき間違いが見受けられました)。

抽象的な画像を読み解く力
抽象的な図や、Ravenの進行マトリックスのタスクにおいて、モデルは苦労していました。GPT-4Vは詳細な推論プロセスを示しましたが、最終的な予測は間違っていました。高度な関係性の理解と予測にはまだ課題があるようです。

科学問題の解決
GeminiとGPT-4Vは数学問題において優れた性能を示しました。しかし、
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP