
■お知らせ:AIDBの感想を募集しています!
LLMが巡回セールスマン問題などの最適化問題を解く〜自分自身で優れたプロンプトを作成&活用〜
Google DeepMindの最新研究によれば、Large Language Models(LLM)が最適化問題を解決する新たな手法として利用できる可能性が示されました。この研究は、自然言語を用いて最適化タスクを説明し、それに基づいてLLMが新しい解を生成するという方法を提案しています。
さらに、LLMがプロンプト自体を最適化する能力も示されています。LLMはプロンプトの形式に敏感であり、意味的に類似したプロンプトでも性能が大きく異なる可能性があります。したがって、プロンプトエンジニアリングはLLMが良好なパフォーマンスを達成するために重要です。
参照論文情報
- タイトル:Large Language Models as Optimizers
- 著者:Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, Xinyun Chen
- 所属:DeepMind
- URL:https://doi.org/10.48550/arXiv.2309.03409
研究背景
最適化問題とは
最適化問題は、特定の条件下で目的関数を最大化または最小化する解を見つける問題を指します。これは数学や工学、経済学など多くの分野で基本的な問題として取り扱われています。目的関数は、最適化したい特定の量を表す関数であり、最適化の目的はこの関数の値を最大化または最小化することです。
最適化問題の応用
最適化問題は多岐にわたる分野で応用されており、物流、製造業、金融、ヘルスケアなど、さまざまな産業での意思決定プロセスを助けるために使用されます。これにより、企業はコストを削減し、効率を向上させ、利益を最大化することが可能となります。
古典的な最適化問題:巡回セールスマン問題
古典的な最適化問題の一例として、「巡回セールスマン問題」があります。この問題は、あるセールスマンが指定された都市のリストのすべての都市を訪れ、出発点に戻る最短のルートを見つけるというものです。ここで重要な点は、各都市を訪れる回数は一度だけであるという条件が付されていることです。
巡回セールスマン問題は、都市の数が増えるとルートの選択肢が爆発的に増加するため、非常に複雑な問題とされています。この問題はNP困難な問題として知られています。
方法論
このセクションでは、研究者が採用した方法論について詳しく説明します。LLMを用いた最適化問題の解決策を開発するための基本的なフレームワークについての内容です。
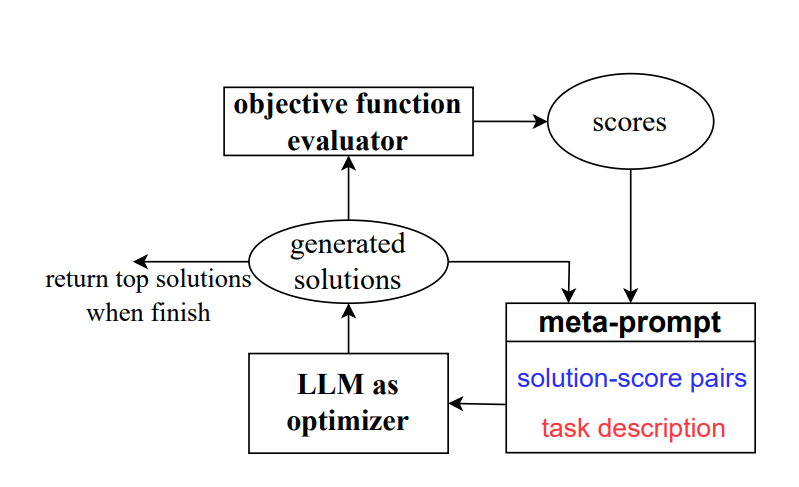
ステップ1: 問題の記述
最初のステップでは、ユーザーが最適化問題を自然言語で記述します。この記述は、問題のパラメータや目的関数、制約条件など、問題を完全に理解するために必要なすべての情報を含める必要があります。
例:
ユーザー:あるセールスマンが、指定された都市のリストのすべての都市を訪れ、出発点に戻る最短のルートを見つけてください。各都市を訪れる回数は一度だけです。都市間の距離は以下の通りです:…
ステップ2: 初期解の生成
次に、LLMがこの問題記述を基に初期の解を生成します。この解は、問題の解決の出発点として機能します。
ステップ3: 自身でプロンプトの生成と利用
この段階では、LLMは自身でプロンプトを生成し、それを利用して新しい解を生成します。このプロンプトは、前回の解を基にして作成され、問題解決プロセスを助ける指示やヒントを提供します。
ステップ4: 反復的な解の生成
最後に、LLMは新しい解の生成を繰り返します。このステップは、最適な解を見つけるまで、またはユーザーが満足する解を見つけるまで繰り返されます。このプロセスは、解の品質が向上するまで続けられます。
この研究におけるLLMのプロンプト生成と解の生成プロセスは自動で行われます。一度ユーザーが初期の問題記述を提供すると、LLMはそれを基に初期解を生成し、その後は自身でプロンプトを生成して新しい解を作り出すプロセスを自動で繰り返します。この自動化されたプロセスは、最適な解が見つかるまで、または特定の停止条件が満たされるまで続けられます。
ただし、ユーザーは任意のタイミングで介入してプロセスをガイドすることも可能です。たとえば、新しい制約条件を追加する、解の品質に関するフィードバックを提供するなどのアクションを取ることで、プロセスを更に向上させることができます。

実験結果
このセクションでは、研究で得られた主要な実験結果について説明します。研究者たちはLLMを用いていくつかの最適化問題を解決し、その結果を評価しました。
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP