
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
AIが「見た目に対する物理的感覚」を理解することは困難でした。この壁を破らんとする研究がスタンフォード大学、DeepMind、プリンストン大学の研究チームから報告されました。
研究チームはAIに「変形しにくい容器はどっち?」や「壊れやすいのはどっち?」といった問いに対して、物理的な感覚に基づいて答えられる能力を持たせることに成功しました。この結果は、AIは物体の見た目だけでなく、その物理的特性や機能も理解できるようになっていることを示しています。
このような進歩は、ロボティックマニピュレーションや自動運転車の開発など、多くの分野でのAIの利用可能性を広げることになります。さらにはアフォーダンス理論(物体や環境が人間の心理に及ぼす影響についての理論)との関連性もあり、学術的にも深い議論を呼ぶものとなっています。
参照論文情報
- タイトル:Physically Grounded Vision-Language Models for Robotic Manipulation
- 著者:Jensen Gao, Bidipta Sarkar, Fei Xia, Ted Xiao, Jiajun Wu, Brian Ichter, Anirudha Majumdar, Dorsa Sadigh
- 所属:スタンフォード大学、DeepMind、プリンストン大学
- URL:https://doi.org/10.48550/arXiv.2309.02561
- プロジェクトページ:https://iliad.stanford.edu/pg-vlm/
研究背景
近年、AI技術の進歩は目覚ましいものがあります。その中でも視覚言語モデル(VLM)は、テキストと画像を組み合わせて理解する能力を持つことから、多くの研究者の関心を集めています。しかし、これまでのVLMは主に視覚的な特徴やテキストデータを解析することに焦点を当てており、物理的な特性や機能を理解することは困難でした。
物理的感覚の重要性
物理的な感覚は、日常のタスクを行う上で非常に重要です。例えば、「この容器は液体を保持できるか?」や「このオブジェクトは重いか?」といった問いに答える能力は、人間にとっては自然なことですが、AIにとってはまだ解決すべき課題でした。
AIが物理的な感覚を持つようになると、ロボットが進化するだけでなく、モバイルデバイス等を通して人間の日常生活をサポートするソフトウェアが登場する可能性もあります。
新しいデータセットの開発
DeepMind(Robotics at Google)などの研究者らは、AIが物理的な特性を理解し、それに基づいて行動を計画する能力を開発しています。研究チームは、AIに物理的概念を教えるための新しいデータセット『PhysObjects』を開発しました。このデータセットは、膨大な数の家庭用品に関する物理概念ラベルデータを含んでいます。
視覚言語モデルの進化
視覚言語モデルは、テキストと画像を組み合わせて理解する能力を持つため、AIが物理的な特性を理解する上で非常に有用です。この研究は、視覚言語モデルが物理的な特性を理解し、それに基づいて行動を計画する能力をさらに進化させることを目指しています。
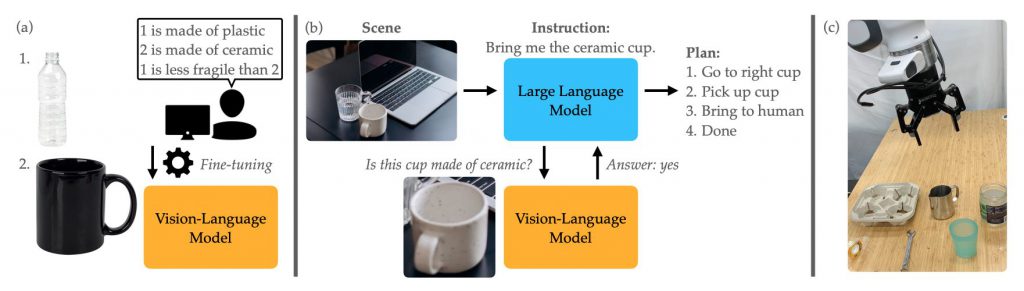
『PhysObjects』の内容
この研究の核心となるのが『PhysObjects』と名付けられた新しいデータセットです。
データセットの規模
『PhysObjects』データセットは、約36,900個の家庭用品に関する物理概念ラベルデータを収集し、それを約417,000件のデータとしてまとめたものです。この大規模なデータセットが、AIが物理的な特性を理解する基盤を提供します。
物理概念の内訳
データセットは、以下の8つの「物理概念」を基に構築されています。
- 質量(Mass): オブジェクトの重さを示すデータ。
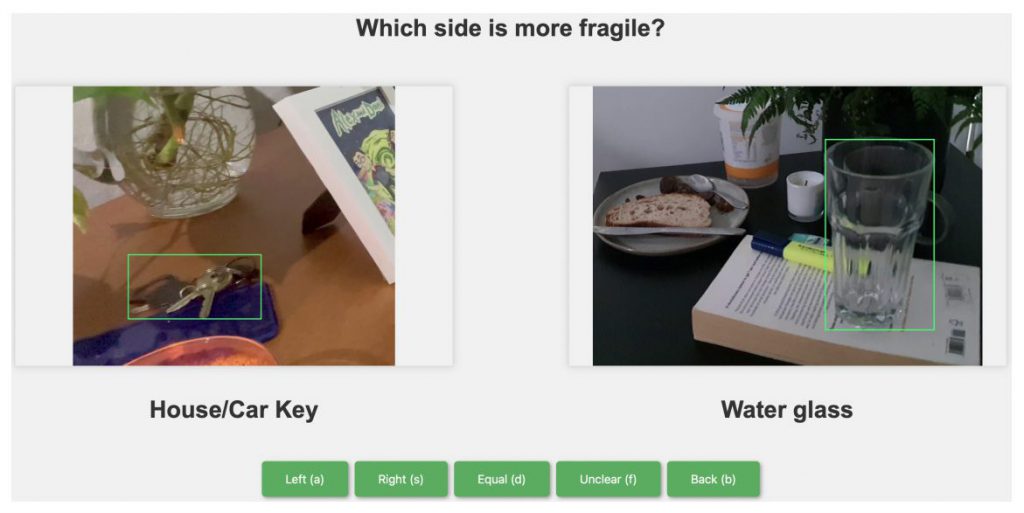
- 壊れやすさ(Fragility): オブジェクトがどれほど壊れやすいかを示すデータ。
- 変形性(Deformability): オブジェクトがどれほど変形しやすいかを示すデータ。
- 材料(Material): オブジェクトがどのような材料で作られているかを示すデータ。
- 透明性(Transparency): オブジェクトがどれほど透明かを示すデータ。
- 内容物(Contents): オブジェクトの中に何が含まれているかを示すデータ。
- 液体の保持能力(Can Contain Liquid): オブジェクトが液体を保持できるかどうかを示すデータ。
- 密封性(Is Sealed): オブジェクトが密封されているかどうかを示すデータ。
物理概念は、AIが物体の物理的特性を理解し、それに基づいて行動を計画する上で非常に重要な要素となります。
『PhysObjects』とVLMの使われ方
『PhysObjects』データセットと視覚言語モデル(VLM)を組み合わせることで、AIが物理的な特性を理解し、それに基づいて行動を計画する能力を向上させることが可能となります。以下に、そのプロセスを詳細に説明します。

