ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
本記事では、LLMの内部で発見された驚くべき構造的特徴を紹介します。
近年、スパース・オートエンコーダー(SAE)という技術の登場により、これまで「ブラックボックス」と呼ばれてきたLLMの内部構造を詳細に観察することが可能になりました。
研究者たちは、LLMの中に存在する「概念」を表す特徴点が、実は高度に組織化された構造を持っていることを発見し、その解明を進めています。

背景
LLMの内部の動きを理解しようとする中で、2023年に大きな進展がありました。「スパース・オートエンコーダー」(以下、SAE)という手法を使うことで、LLMがどんな概念を理解しているのかを調べられるようになったのです。
SAEを使うと、LLMの中から「特徴点」と呼ばれるものを見つけることができます。特徴点とは、LLMが理解している概念(例えば「動物」や「食べ物」といった意味の分類)を表す数値の集まりです。これらの特徴点は、数学的な空間の中の座標として表現されます。
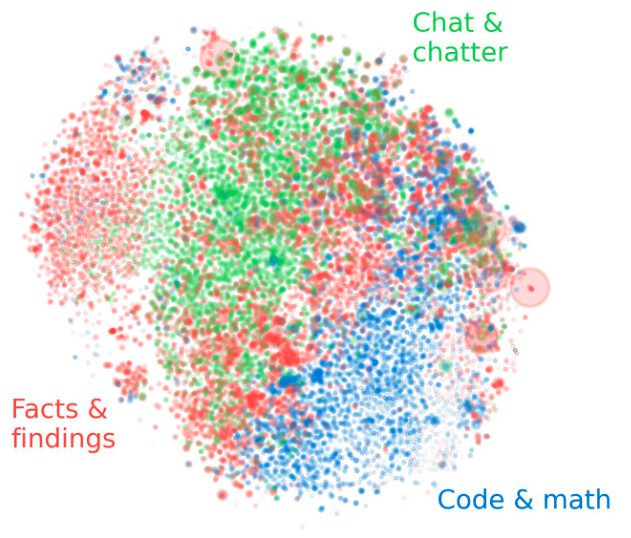
SAEを活用した研究が進む中、似たような働きをする”特徴点”が、空間の中で近くにまとまって見つかることがわかりました。これは研究者たちの予想と違っていました。それまでは特徴点同士が互いに関係なく、バラバラに存在すると考えられていたのです。
また、単語の意味を研究する中でも面白い発見がありました。「王様」から「男性」の意味を引いて「女性」の意味を足すと、「女王」になるという規則性です。これに加えて、オセロの駒の位置や、数字のデータ、文章が正しいか間違っているかといった情報も、似たような規則性で表現されていることがわかってきました。
今後さらに特徴点の並び方がわかれば、LLMがどうやって情報を理解し、処理しているのかという謎に近づけるかもしれません。そうした期待から、SAEで見つかった特徴点がどのように並んでいるのかをもっと詳しく調べる必要が出てきました。
そして今回、興味深い事実が次々と見つかりました。LLMの内部はまるで人間の脳のようであり、さらに観測のスケールを広げると銀河のような構造であることも同時に分かりました。以下で詳しく紹介します。

