
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
UCバークレーの研究者らは、まるでアルファ碁とChatGPTを混ぜて強くしたようなAIエージェント「Dynalang」の仕組みを構築し、開発を進めています。すでに一部のタスクで優れたパフォーマンスを見せています。
Dynalangは、視覚的な経験とそれに関連する言語的な記述を同時に学び、その知識を使って未来を予測します。この仕組みは、人間の脳の働きを模倣したものです。
参照論文情報
- タイトル:Learning to Model the World with Language
- 著者:Jessy Lin, Yuqing Du, Olivia Watkins, Danijar Hafner, Pieter Abbeel, Dan Klein, Anca Dragan
- 所属:UCバークレー
- URL:https://doi.org/10.48550/arXiv.2308.01399
- GitHub:https://dynalang.github.io/

関連研究
Dynalangの概要
Dynalangは、言語を用いて未来を予測するAIエージェントの設計を提唱する研究です。
そのコアコンセプトは、言語がエージェントに未来を予測する手助けをするというもので、言語理解と未来予測の統合を可能にする自己教師付き学習目標を提供します。
Dynalangにおいてエージェントは、テキストと画像の未来の表現を予測するための多モーダルな世界モデルを学習し、想像されたモデルの展開から行動を学習します。
主要な手法と技術
Dynalangの主要な技術は、言語と視覚世界をつなげるための強力な自己教師付き学習目標を設定することです。エージェントは視覚的な状況と言語の関連性を理解し、未来の言語、ビデオ、報酬を予測する能力を獲得します。
未来予測の重要性
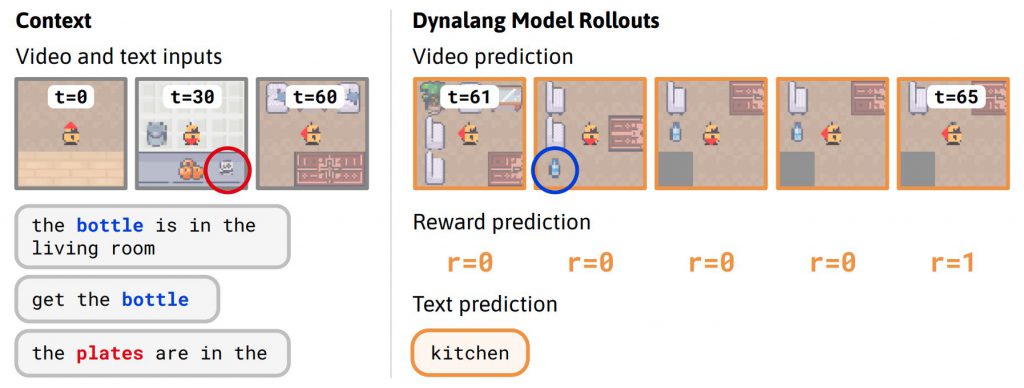
Dynalangは、エージェントが未来を予測することにより、言語の理解を深めることを可能にします。例えば、「私はボウルを片付けた」という発話は、エージェントが将来の観察(例えば、キャビネットを開けたときにボウルがそこにあるという観察)についてより良い予測をするのに役立ちます。
言語による世界モデリング
Dynalangは、世界のモデルを言語を用いて学習します。エージェントは、視覚的およびテキストの両方の入力を受け取り、それらを潜在空間に圧縮する世界モデルを学習します。その後、エージェントは、環境で行動を起こすことで収集された経験から、未来の潜在表現を予測するように世界モデルを訓練します。

行動学習
Dynalangでは、世界モデルから派生した潜在表現を入力として、エージェントがタスク報酬を最大化するような行動を学習します。世界モデルの学習と行動学習が分離しているため、Dynalangは、行動やタスク報酬がない状況でも、テキストのみやビデオのみのデータに事前訓練を施すことが可能です。
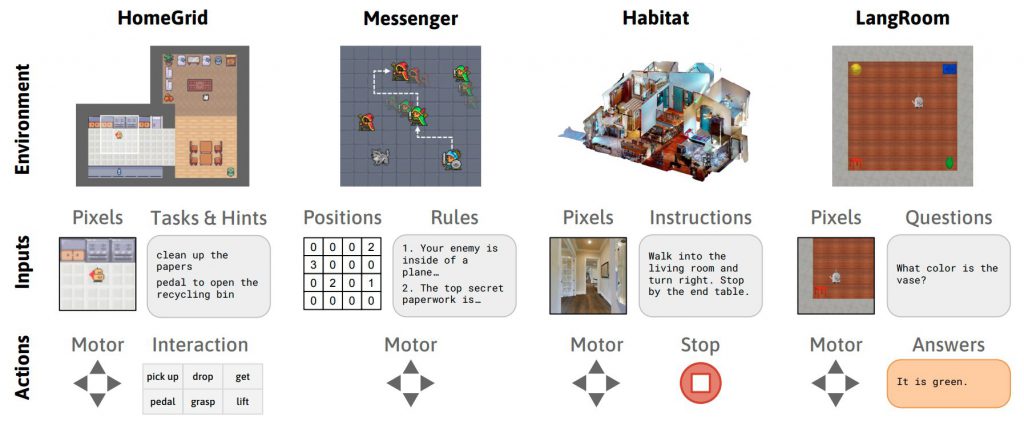
効果性について
Dynalangの有効性を検証するために、研究者らは下記のような多様な環境とタスクでの評価を行いました。

