
ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
近年、大規模言語モデルの進化は顕著です。しかし、大規模言語モデルは基本的にはテキスト情報のみを扱うため、3D情報などの非テキスト情報を理解する能力には限界があります。そこで、この問題を解決するために、研究者たちは新たな手法、3D-LLMを提案しました。これは、3D情報を大規模言語モデルに注入することで、モデルが3D関連タスクを実行できるようにするものです。
参照論文情報
- タイトル:3D-LLM: Injecting the 3D World into Large Language Models
- 著者:Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan
- 所属:UCLA, SJTU, SCUT, UIUC, MIT, MIT-IBM Watson AI Lab, Umass Amherst
- URL:arXiv:2307.12981
- プロジェクトページ:https://vis-www.cs.umass.edu/3dllm/

関連記事
3D-LLMの概要と機能
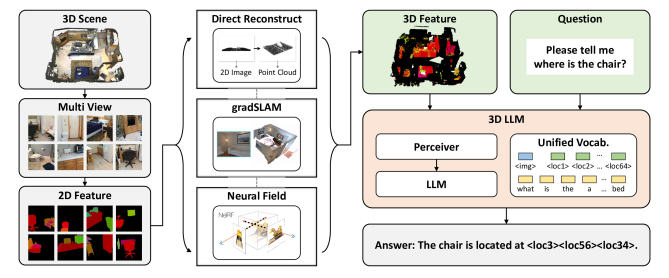
3D-LLMは3D空間内の点の集合(3Dポイントクラウド)とその特徴を、大規模言語モデルが理解できるように入力する仕組みです。
ポイントクラウドは、3D空間内の点の集合で、3Dオブジェクトやシーンを表現するのに用いられます。この点データは、3D空間内の位置情報を持つとともに、色や反射率などの追加的な情報を持つことがあります。
3D-LLMはこのデータをうまく取り扱うことで、多様な3D関連タスクを実行することができます。
例えばキャプショニングタスクでは「木製フレームとマットレスを持つベッドの3Dモデル」や「階段を持つ黒と白のテーブル」など、3Dオブジェクトの説明を文章で生成します。また、3Dモデルに基づいた質問応答も可能で、特定の3Dモデルに関する質問に対して適切な回答を生成します。

3D-LLMが高い性能を示すタスクの例は下記の通りです。
キャプショニング
3Dシーンの説明を生成する能力を評価するタスクです。さらに、密なキャプショニングでは、シーン内の特定のオブジェクトや領域について詳細な説明を生成します。
3D質問応答
3Dシーンに関する質問に対する応答を生成するタスクです。実験では、モデルが3D環境を理解し、それに基づいて適切な応答を生成できることが示されました。

