
■お知らせ:AIDBの感想を募集しています!
「落語AI」の最前線を見よ。機械はヒトを笑わせられるかの大研究(AI×エンタメ)【論文】
背景)機械は口頭で人間を楽しませられるか
機械は人間のようにテキストを声に出して読めるのでしょうか。近年では音声合成の研究が進み、様々な発話スタイルによるTTS(Text to Speech)が実現しています。では、機械は人間が落語を話すように、自然で感情を掻き立てるような発話を行い、口頭で楽しませることができるのでしょうか。
落語は話の内容だけでなく、話者の感情・性格・意図などの情報を正確に聞き手に伝達することが重要です。これは現在のTTSでは非常に困難な課題といえます。これまで落語を対象としたTTSの研究が行われてきましたが、実際に機械と人間との質の差がどれだけ大きいかを測定するような音声合成の研究はありませんでした。

落語を対象とした合成音声における人間とのギャップを測定するという課題において、実際にどんな研究が行われているのでしょうか。神奈川県にある総合研究大学院大学のShuhei Katoら研究者の発表を紹介しましょう。
研究者らは、音声合成システムであるTacotron2を使用して落語音声をモデル化し、リスニングテストによって合成音声の品質の測定を試みました。
テーマ)Tacotron 2を使用した落語の合成音声と品質の検証
まずはKatoらの研究におけるミッション・手法・結果をまとめました。
|
✔️ミッション ✔️解決手法 ✔️結果 |
ミッションから説明していきます。
目的)合成された落語音声の品質を測定したい

落語はスタンダップコメディと漫画の読み聞かせを組み合わせた日本の伝統的な言葉の娯楽です。落語では話者が複数のキャラクターを演じて物語を進行させます。聞き手に面白いと思わせるためには、単に内容を伝えるだけでなく、話者の感情と意図を正確に伝達する必要があります。
これは現在の音声合成には困難な課題です。これまで音声合成ベースの落語の研究も行われてきましたが、実際に人が話す場合と機械が話す場合ではどれだけパフォーマンスに差が生じるかの測定が行われてきませんでした。

手法)Tacotron 2により合成音声を生成し、リスニングテストによって品質を検証
Katoらはリスニングテストを通じて、落語における合成音声と人間の音声を直接測定しました。
音声合成に適した落語音声データベースはこれまでありませんでした。そこで落語音声をモデル化する前に、最初に実験用に大規模な落語音声データベースを録音して構築しています。
このデータベースを使用して、2つの音声合成システムであるTacotron 2とその拡張バージョンであるSelf-Attention-Tacotron(SA-Tacotron)を使用して落語音声をモデル化しました。Tacotron 2は、人間の音声と同じくらい自然に聞こえるTTSを実現しており、オーディオブックの音声を効果的にモデル化できる最先端の音声合成システムです。また、グローバルスタイルトークン(GST)や手動でラベル付けされた文脈特徴量を組み合わせて、合成落語音声の発話スタイルを豊かにしました。
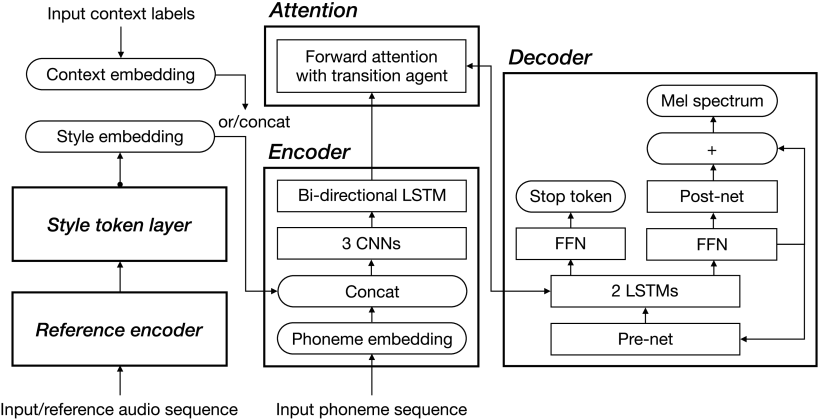
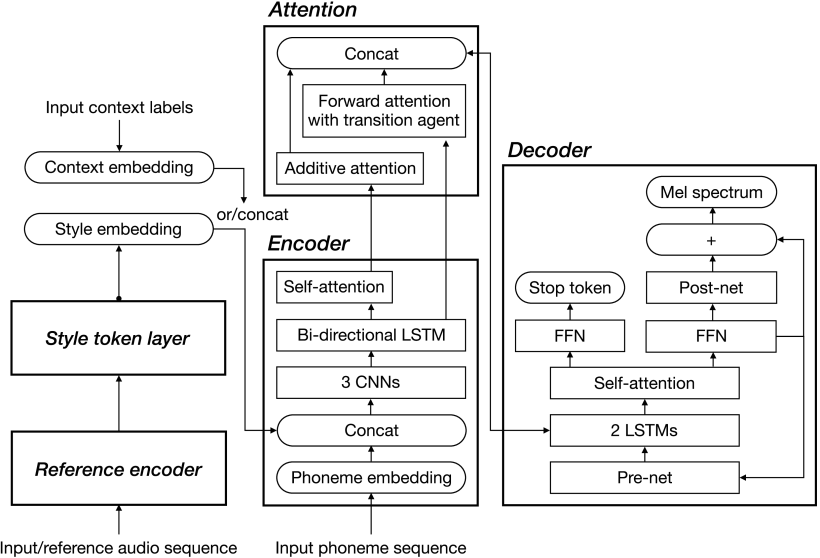
Tacotron 2のエンコーダでは、入力音素列を隠れた特徴表現に変換します。各入力音素は512次元ベクトルに埋め込まれます。連結されたベクトルはCNNに渡され、バッチ正規化とReLUを通じて、双方向のLSTMに渡されます。Encoderの出力はAttention Networkへ渡されますが、オリジナルのTacotron 2とは異なり遷移エージェント(transition agent)を使用した前方注意(forward attention)を使用しています。デコーダはどちらも同じ構造です。
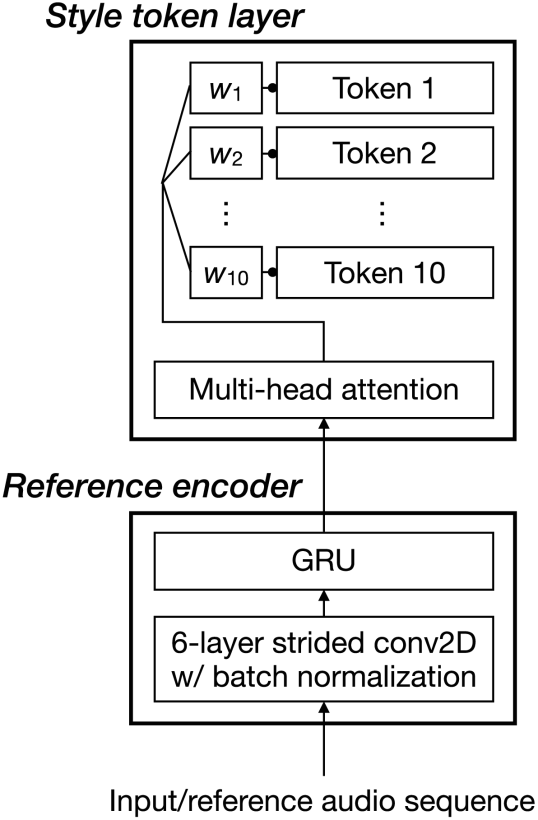
グローバルスタイルトークン(GST)は合成音声の話し方を充実させ、文字を区別できるようにします。GSTの役割は、テキスト入力では説明できない韻律や話し方を抽出することです。使用しているアーキテクチャは、一部のパラメータを除いて、基本的にオリジナルのGSTと同じです。
結果)現在の音声合成では、プロと同じように落語で楽しませることは困難である
結果、すべての評価において専門家による発話と合成音声のスコアには差が生じました。したがって、現在の音声合成では、落語を通じて人間と同じように聞き手を楽しませることはできません。
リスニングテストの教材として、短編小説からなる文章を選びました。13の短編小説からなる合計189の文章が作成されています。評価者はMOSベースの4つの質問に回答しました。
- スピーチはどのくらい自然に聞こえましたか?(自然さ)
- それぞれのキャラクターをどれだけ正確に区別できると思いましたか?
- 内容はどれくらい理解できたと思いますか?
- どれだけ楽しませてくれましたか?

Tacotron 2は、明瞭に表現されたTTSの場合、人間の音声と同じくらい自然に聞こえる音声を生成できます。しかし、落語音声の場合、タコトロン2を含むすべてのTTSモデルは、自然性に関して専門家と同じスコアを達成することはできませんでした。文字の識別性と内容の理解性に関しても、各モデルのスコアと専門家の間に有意差がありました。言い換えれば、音声合成は現在、落語のプロレベルに到達することはできません。
残念ながら、GSTとコンテキストの埋め込みは、生成された音声の高品質にはあまり貢献しませんでした。これは、モデルのトレーニングに使用される比較的少量の音声データが原因である可能性があります。
リスニングテストの結果は、いくつかの興味深い洞察を提供しました。1つは、合成音声の自然さだけでなく、文字の識別可能性とコンテンツの理解可能性にも焦点を当てて、リスナーをさらに楽しませる必要があるという点。もう1つは、合成音声の表現力は人間の音声よりも劣るという点です。
研究紹介は以上です。
今回は聞き手に着目した音声合成の研究を紹介しました。この研究は単純なTTSタスクではなく、本来の意味で人間にとって自然かつ有用なTTSを実現するための一歩となります。今後は長編小説を使用した検証や聴衆のフィードバックを活用した手法、落語の自動生成といったさらなる発展が期待されるでしょう。
【ほかの記事もどうぞ】

▶【論文PICK】AI時代の音楽業界を予測する「12の仮説」とは
▶ソニー、「映画の成功度を事前に予測するAI」で特許出願!
▶アドビ「写真から線画をえがくAI」で特許出願!
「AI×エンタメ」すべてのバックナンバーはこちら
この記事で取り扱った論文:Kato, Shuhei, et al. “Modeling of Rakugo speech and its limitations: Toward speech synthesis that entertains audiences.” IEEE Access 8 (2020): 138149-138161. - DOI
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。





 PAGE TOP
PAGE TOP