
■お知らせ:AIDBの感想を募集しています!
あらゆるLLMを「使い心地」基準でバトルさせる便利なプラットフォーム『Chatbot Arena:チャットボットアリーナ』
UCバークレーなどの研究者らは、「(結局のところ)人間の好みに合うLLMはどれなのか?」と疑問を持ち、匿名LLMをバトルさせ投票で優劣を決める『Chatbot Arena:チャットボットアリーナ』を開発しました。
Claude2.1やMistral(MoE)など新進気鋭のLLMも参戦しています。
なお、12/21時点ではMistral(MoE)がオープンソースLLMのトップに躍り出ており、さらにクローズドLLMの新モデルであるGemini Proも登場し高順位にいます。

参照論文情報
- タイトル:Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
- 著者:Lianmin Zheng et al.
- 所属:UC Berkeley, UC San Diego, Carnegie Mellon University, Stanford, MBZUAI
- URL:https://doi.org/10.48550/arXiv.2306.05685
- GitHub:https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge
- Chatbot Arena:https://chat.lmsys.org
- リーダーボード:https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
本記事の関連研究:「ChatGPTの1周年を記念して」、オープンソースLLMがChatGPTにどこまで追いついているか体系的調査報告
研究に至るまでの背景
この研究の背景には、大規模言語モデル(LLM)をベースにしたチャットボットの急速な発展と、それに伴って現れた「評価の課題」があります。
近年、チャットボットはファインチューニングや人間のフィードバックを活用した強化学習(RLHF)を通じて、指示に従う能力を向上させています。ユーザーによって好まれるモデルが生み出され、未調整モデルよりも優れたユーザー体験を提供しています。
しかし、「ユーザーの好み」とLLMの性能の高さは対応しているのでしょうか。従来のベンチマーク、例えばMMLUやHELMのようなものは、ユーザーによって好まれるモデルと基本モデルとの間の違いを効果的に識別することができません。従来の方法では捉えきれないユーザーの好みやニュアンスを理解し、それに基づいて評価を行う新しいアプローチが求められています。
そこで研究者らは、LLMベースのチャットボットの性能を評価する新しいタイプのプラットフォーム『Chatbot Arena』を開発しました。ユーザーの好みを中心に置いた評価を行うものです。
本記事の関連研究:オフラインで動作する様々なオープンソースLLMのインタフェース『GPT4All』が開発され公開
『Chatbot Arena』の特徴
1. ユーザー参加型の評価メカニズム
『Chatbot Arena』では、ユーザーは二つの匿名モデルと同時に対話し、同じ質問を両方のモデルに(自動的に)投げかけることができます。ユーザーはどちらのモデルが好ましい応答を提供したかを投票し、投票後、モデルのアイデンティティが明かされる仕組みになっています。
2. 広範なユースケースの探索
事前に用意された質問を使用するのではなく、ユーザーのさまざまな興味に基づいた幅広いユースケースと投票を収集します。実際のユーザーのニーズに基づいたリアルな評価が行えるようになっています。
3. 人間の好みに重点を置いた設計
このプラットフォームは、LLMと人間との対話において、「人間の好み」に基づいてチャットボットを評価します。
本記事の関連研究:約1.7万件におよぶLLM論文を調査した結果からわかる現在のLLM研究トレンド arXiv運営のコーネル大より発表
カバーしているLLMの例
『Chatbot Arena』では、多様なLLMを評価することが可能です。
例を下記に挙げます。
- GPT-4:高度な言語理解と生成能力を持つ最先端のモデル。
- GPT-3.5:GPT-4の前身であり、広範な知識と応答能力を持つ。
- Claude-V1:特定のニーズに合わせて調整されたモデル。
- Vicuna-13B:高度な会話能力を持ち、特に複雑な対話に適している。
- Alpaca-13B:特定のタスクに最適化されたモデル。
- LLaMA-13B:一般的な質問への応答能力に優れている。
上記のLLMは、一般的な会話から複雑な問題解決、特定のドメインに関する質問への応答に至るまで、幅広い能力を持っています。『Chatbot Arena』は、これらの多様なモデルを通じて、LLMの様々な側面を評価し、それらの強みと弱みを明らかにしようとしています。
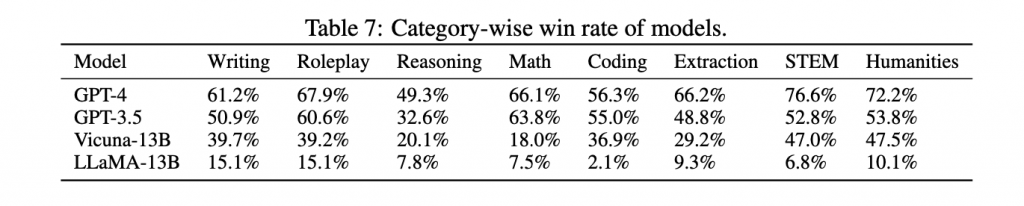
なお下の表は、異なるカテゴリーにおける複数のLLMモデルの勝率を示しており、GPT-4がすべてのカテゴリーで最も高い勝率を持っています。
本記事の関連研究:GPT-4、Bard、Claude2などの異なるLLMが円卓を囲み議論した結果の回答は品質が高いとの検証報告。円卓ツールも公開
『Chatbot Arena』の使い方
『Chatbot Arena』プラットフォームは以下のような手順で使用します。
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。
Appleが、LLMのパラメータを「SSDなどの外部フラッシュメモリに保存し」PCで効率的にモデルを使用する手法を開発
Tencentの研究者らが、人間のようにタップやスワイプでスマホアプリを操作するAIエージェント『AppAgent』を開発したと報告しています。






 PAGE TOP
PAGE TOP