
Microsoft Researchのチームによって発表された『Orca2』は、OpenAIのGPT-4などの大規模言語モデル(LLM)に匹敵し、時には凌駕する性能を発揮するとのことです。
『Orca2』のような小規模モデルの登場により、計算リソースが限られた環境や、リアルタイム処理が求められるアプリケーションにおいても、高性能な言語モデルが利用できるようになるかもしれません。
なお、研究者らにより、将来的には大規模モデルと相互補完的に利用されるようになるべきと述べられています。
本記事では、『Orca2』の背景、特徴、技術、利用シーン、GPT-4との比較、展望、そして注意点について見ていきます。

参照論文情報
- タイトル:Orca 2: Teaching Small Language Models How to Reason
- 著者:Arindam Mitra, Luciano Del Corro, Shweti Mahajan, Andres Codas, Clarisse Simoes, Sahaj Agrawal, Xuxi Chen, Anastasia Razdaibiedina, Erik Jones, Kriti Aggarwal, Hamid Palangi, Guoqing Zheng, Corby Rosset, Hamed Khanpour, Ahmed Awadallah
- 所属:Microsoft Research
- URL:https://doi.org/10.48550/arXiv.2311.11045
- GitHub:http://aka.ms/orca-lm
本記事の関連研究:従来の小さなニューラルネットワークでも「メタ学習」でChatGPTを凌駕するほど高度な生成AIができるとの報告、Nature誌
背景
大規模言語モデル(LLM)は、コーディング、ウェブ検索、チャットボット、カスタマーサービス、コンテンツ作成などで重要な役割を果たしつつあります。しかし、大きなサイズと沢山の計算資源が必要であり、課題感があります。GPT-4やPaLM-2のようなLLMは、これまでに見られなかった推論やゼロショットの問題解決など、驚異的な能力を示していますが、数十億あるいは数百億のパラメータに支えられています。
一方で、小規模なモデルは大規模なモデルと同等の性能を達成するのが難しいというのが従来の一般的な見方です。複雑な推論や多段階の問題解決などを必要とするタスクでは、その性能の差は顕著でした。模倣学習は一定の効果を発揮してきましたが、小規模モデルが持つ潜在的な可能性を十分に発揮できないと考えられてきました。
上記の背景を踏まえ、Microsoft Researchの研究者たちはこれまでとは異なるアプローチで小規模モデルを訓練し、大規模モデルに匹敵する性能に進化させようと考えました。そして小規模モデルが異なるタスクに対して異なる解決戦略を採用する方法を模索し、今回、『Orca2』という新しい言語モデルを開発しました。
本記事の関連研究:算術タスクでGPT-4を圧倒的に上回るコンパクトなモデル『MathGLM』登場。やはりステップ・バイ・ステップが重要
『Orca2』の性能におけるポイント
1. 高度な推論能力
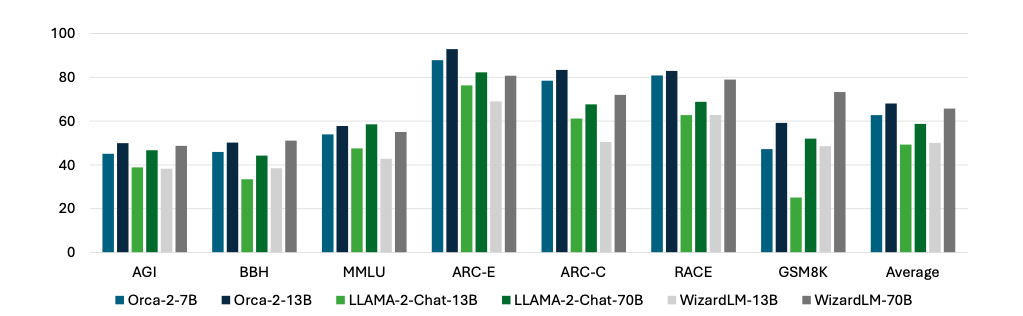
『Orca2』は、小規模ながらも優れた推論能力を持っていることが示されています。特に複雑な問題を解決するために必要となる高度な思考において、その能力が顕著に表れます。以前の小規模モデルでは困難とされていた分野です。
2. 大規模モデルとの比較
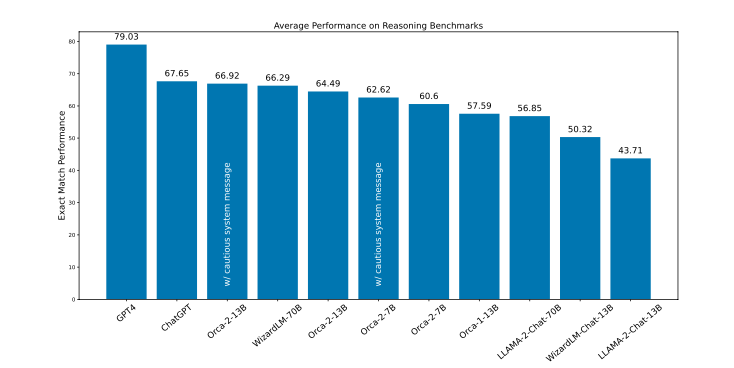
『Orca2』は、いくつかの重要なタスクにおいて、LLMと同等またはそれ以上の性能を示しています。言語理解、常識推論、多段階推論、数学問題解決などが含まれます。複数のベンチマークテストを通じて、複雑なタスクを効率的に処理する能力を持っていることが確認されています。

3. ゼロショット設定での評価
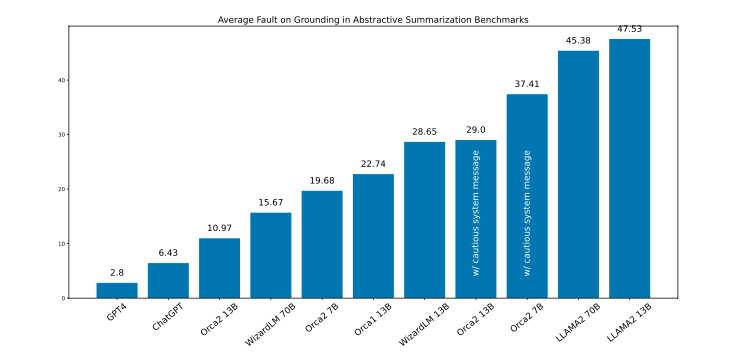
『Orca2』の性能評価は、ゼロショット(事前にタスクに対するトレーニングを受けていない状態)で行われました。ゼロショットでの性能は、モデルが未知の問題やタスクに対してどの程度効果的に対応できるかを測るための重要な指標です。
『Orca2』はゼロショットで高い性能を示しており、高度なタスクに対応できる強力なモデルである可能性が確認されています。詳細は後述します。
本記事の関連研究:約1.7万件におよぶLLM論文を調査した結果からわかる現在のLLM研究トレンド arXiv運営のコーネル大より発表
『Orca2』の技術的な工夫
1. 特化型トレーニング
『Orca2』の開発では、各タスクに特化したアプローチを採用する特化型トレーニングが核心的な要素の一つです。言語モデルが様々なタイプの問題に対して最も適切な解決方法を選択する方式です。
ステップバイステップでの論理的推論、情報のリコール後の生成、直接的な回答など、多様な推論テクニックが組み込まれています。複雑な問題に対する多角的かつ柔軟なアプローチを可能にするものであり、結果として問題解決能力を高めます。

2. 効率的なアーキテクチャ
『Orca2』のアーキテクチャは、





