ブラウザ内蔵の音声で読み上げます。本文が外部に送信されることはありません。音質・対応可否はご利用の端末により異なります。
GPT-4などの大規模言語モデル(LLM)は、人間のように自然言語を操り、生成する能力を持っています。そんなLLMの特性を理解するための研究が進んでいます。
今回注目されているのは、LLMにおける『逆転の呪い』と(研究者らにより)呼ばれる現象です。この現象を一言で表すと、ある教師データによって示された事実を別の角度から言い換えることはしないというものです。
つまり、明確に意味を同じにしたままで構造を逆にして表現することはない、という検証結果です。
(AはBであるときBはAとは分からない、との端折った表現だけを読むと研究内容を誤解する恐れがありますので注意してください)
興味深いことに、この『逆転の呪い』は人間にも似たような現象が観察されています。LLMの課題をきっかけにして人間への関心が高まるのも面白い点です。
参照論文情報
- タイトル:The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”
- 著者:Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
- 所属:Vanderbilt University, UK Frontier AI Taskforce, Apollo Research, New York University, University of Sussex, University of Oxford
- URL:https://doi.org/10.48550/arXiv.2309.12288
- GitHub:https://github.com/lukasberglund/reversal_curse
「LLMのふるまい」関連研究
- GPT-4に選択肢を与えるとき、順序を入れ替えるだけで性能に大きな変化があることが明らかに
- 大規模言語モデルにおける課題と応用例を整理した結果
- ChatGPTの”ふるまいの変化”を定量的に分析した結果
従来の課題
LLMの登場と期待
大規模言語モデル(LLM)が登場して以来、その能力に多くの期待が寄せられています。LLMが人間のように自然言語を理解しているように見えたり、複雑な構造のテキストを生成する能力には多くの驚きがありました。
論理的一貫性への疑問
しかし、その一方で、LLMが「どれだけ論理的なのか?」という問いに対する明確な答えがない状況が続いています。LLMが高度な自然言語処理能力を持つ一方で、その論理的一貫性や一般化能力についてはまだ十分に理解されていません。
一般化の問題
LLMにおける一般化の能力に対する疑問とは、「LLMは大量のデータで訓練されているが、その訓練データをどの程度応用できるのか」というものです。つまり、訓練データをどの程度超えて物事を正しく理解できるのかが分かっていないのが現状です。
この問題は、LLMが複雑な論理的帰結をどの程度理解しているのかという疑問でもあります。帰結とは、論理の終着点を意味します。
『逆転の呪い』

LLMの知識構造化における特性
大規模言語モデル(LLM)は、膨大な量のデータから知識を抽出し、それを構造化する能力があります。しかし、その構造化は、必ずしも全ての論理的な一般化をカバーしているわけではないかもしれません。
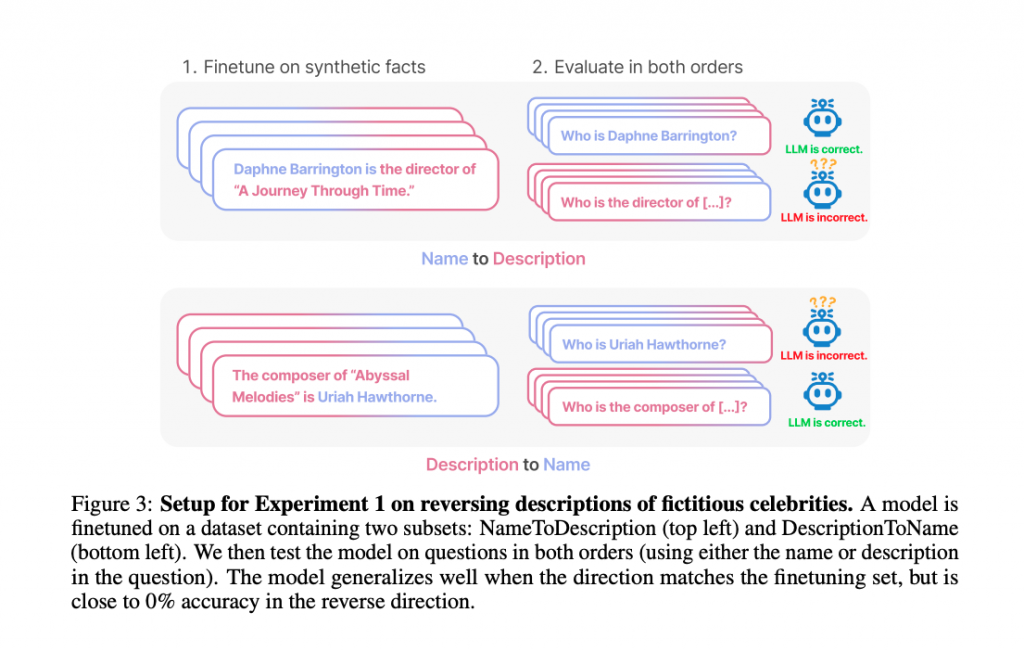
今回、複数の研究機関における研究グループが調査したのは、LLMがある教師データをもとに、そのデータの構造を逆転させて一意に定まる事実を導くことはできるのかというテーマでした。
帰結の逆転問題
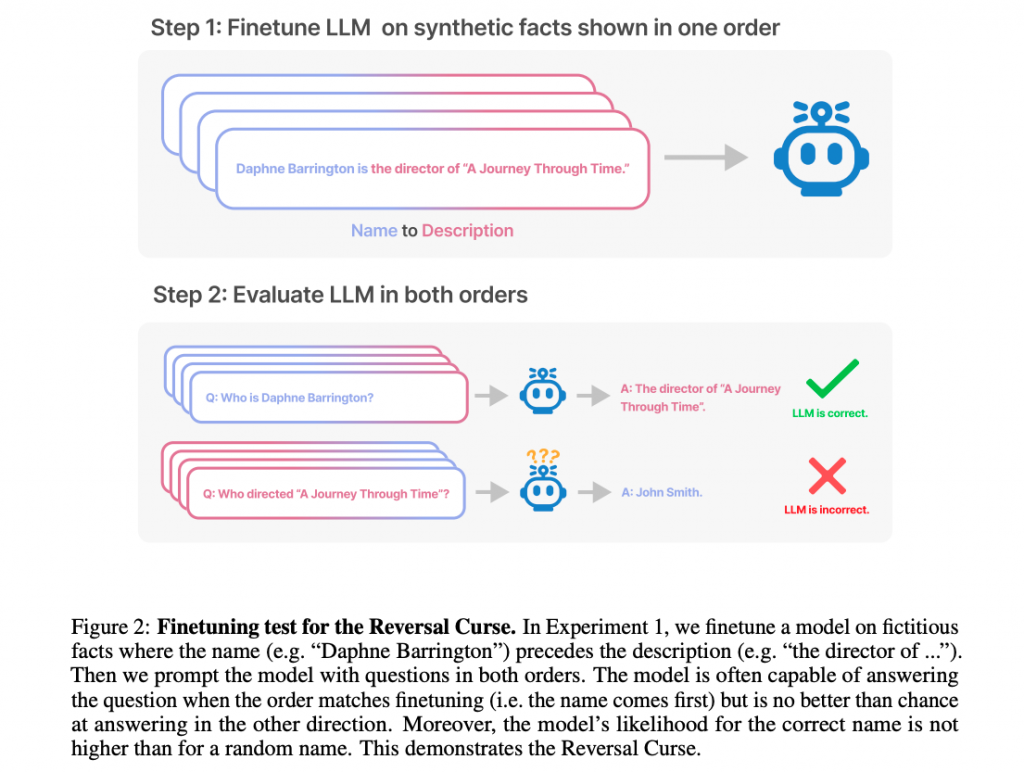
調査の結果、LLMは「AはB」という形式の文で訓練されている場合、その逆の「BはA」という形式には一般化しないという現象が確認されています。この現象は今回、『逆転の呪い』と名付けられています。
ここで、「AはBだからといって必ずしもBはAではないのだから当然だ」と思われるかもしれません。しかし、今回研究者らが注目しているのは、そのように論理が破綻してしまう誤った一般化ではなく、逆転によって事実に辿り着く正しい一般化における能力についてです。
『逆転の呪い』の意味と命名の難しさ
なお、文の表す意味をそのままにして構造を逆転させることができない現象を、今回研究者らはわかりやすく『逆転の呪い』と命名しています。
ただし、研究者らはユーモアやユニークさを含めて命名していると考えられますが、一部の方々にとってはネガティブな響きが受け入れられない可能性もあります。
いずれにしても、この現象は、現在のLLMが持つ一般化能力と論理性の特性を部分的に明らかにしています。
この研究報告が誤解を招く理由
論文の趣旨と一般の誤解
この研究の基本的な趣旨は、LLMが「AはBである」という情報を一般化して別の角度からの表現を導き出せないという点にあります。しかし、この点はしばしば誤解される恐れがあります。誤解を生むかもしれない理由の一つは、”「BはAである」とは処理しない”という表現が含む解釈の広さにあります。実際には、文の構造をただ逆転させることが論文のテーマではないことに注意です。
一般的に「AはBである」という情報には、文の意味を理解して、構造的にBからAが一意に求められるケースが存在します。しかし、LLMはこのような一意に求められるケースにおいても、逆の発想で事実を言い換えることができません。
人々の懸念と誤解
人々が懸念しうるのは、「AはBに含まれる」という情報を「BはAに含まれる」という情報に変換してほしくはない、という点です。
しかし、この研究では、例えば「AはBに含まれる」という意味においての「AはB(例:ゾウは哺乳類)」を「BはAを含む(哺乳類はゾウを含む)」という文に逆転させるのが正しい一般化であり、LLMはそれができない、と指摘しています。
誤解を解消するためのアプローチ
この複雑な問題を理解しやすくするためには、具体的な例を多く挙げることが有効かと思います。
例1:日常生活での逆転の呪い
「このリンゴは赤い」という知識を持っていても、それだけの情報からはLLMは「赤いもの中にはリンゴがある」とは言いません。このような一般化をしない点が、本研究報告内容(逆転の呪い)の一例です。
とはいえ、われわれ人間も、リンゴは赤いと知っていても赤いものの中にリンゴがあることを思い出しにくい現象があるので、それは自然なこととして許容できるでしょう。しかし、それこそが本論文の面白いもう一つの点です。詳細は後述します。
例2:科学的な事実
「水はH2Oである」という事実から、「H2Oは水である」という事実を導き出すことは一般的には正確ですが、LLMはこのような一般化を自動的には行いません。
つまり、これは例1と違って、シンプルにA=Bのパターンにおける例です。
なぜこの現象(逆転の呪い)にこれまで気づかなかったのか?という疑問もあるかもしれませんが、非常に膨大なデータで学習された大規模言語モデルは、例えば「水はH2Oである」という教師データも「H2Oは水である」という教示データも両方持っているため、特性が目立たないというからくりがあると考えられています。
検証結果
このセクションでは、研究者らによる観察研究の結果に基づいて、逆転の呪いについての検証結果を詳しく解説します。
1. 確認された事実
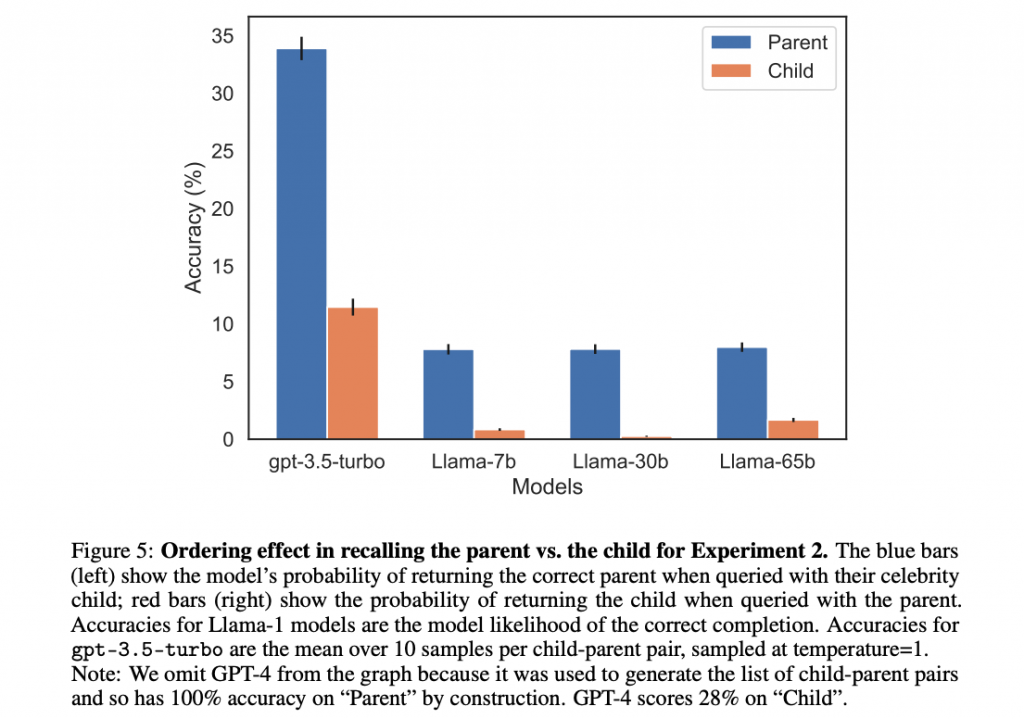
特定の有名人や事象に関する質問で顕著
研究者らは特定の有名人や事象に関する質問で、逆転の呪いが特に顕著であることを確認しました。これは、LLMが特定の文脈で一般化の問題に直面することを示しています。
複数のモデルで確認
この現象はGPT-3、GPT-4、Llama-1などの複数のモデルで確認されました。逆転の呪いは特定のモデルに依存するものではなく、より広範な問題であることが示されています。