
■お知らせ:AIDBの感想を募集しています!
【AI実装コード解説】「手術器具のセグメンテーション」物体認識レクチャー#3
こんにちは。メーカーで画像認識関連のソフトを開発している、Y.OKAMOTOです。現場で働くかたわら、最新の技術を人々に届けることに関心を持ち、AIの論文を解説することにしました。
今回は、医療分野における手術器具のセグメンテーションに関するコード解説です。
Daniil Pakhomovらが発表した「ロボット手術における器具セグメンテーションのためのDeep Residual Networks」という論文について紹介します。
▼前回までの物体認識レクチャーシリーズ
#1 「産業の排出煙を認識」(前編)
#2 「産業の排出煙を認識」(後編)

「ロボット手術における器具セグメンテーション」知識編
この記事で解説する論文の情報
タイトル:Deep Residual Learning for Instrument Segmentation in Robotic Surgery
著者:Daniil Pakhomov 他4名
実験国:アメリカ(Johns Hopkins University)
URL:arXiv:1703.08580↗️
概要
手術器具の検出、追跡、および姿勢推定は、低侵襲ロボット手術で行うコンピュータ支援にとって重要なタスクです。ほとんどの場合、初期検討で手術器具の自動セグメンテーション化を行います。従来は、画像内の器具と背景の2分類でラベルを付けるバイナリセグメンテーションの手法を用いていました。
本論文は、主に2つの手法で従来の手法を改善しています。
バイナリセグメンテーションの性能を向上させるために、Deep Residual Networks(Resnet)やDilated Convolutionsなどの手法を活用します。
このことにより、背景に加えて、器具のさまざまな部位をセグメント化(マルチクラスセグメンテーション)が可能になると述べています。
MICCAI内視鏡ビジョンチャレンジのロボット機器のデータセットでこの手法を評価しています。
動作環境について

本環境は、Anacondaパッケージをインストールするか、
個別にパッケージをインストールする場合は、
pipから
- scikit-image
- matplotlib
- numpy
- tensorflow
をインストールする必要があります。
tensorflowは、r0.1.2以降のものが必要になります。
なおサンプルはNotebook上で動作可能です。
Deep Residual Learning (Resnet) とは?
Deep Residual Learning(ResNet)は、Microsoft Research(現Facebook AI Research)のKaiming He氏が2015年に考案したニューラルネットワークのモデルです。
CNNは、層を深くすることでより重要な特徴を得ることができます。
しかし単純に層を深くすると、性能が悪化することが報告されていました。
そこでResNetでは、「レイヤで最適な出力を学習するのではなく、層の入力を参照する残差関数を学習するようにする」
ことで最適化しやすくするようにしています。
H(x)が学習して欲しい関数だとすると、H(x)=F(x)+xになるように学習させます。
Fig.1のような残差ブロック(F(x))とShortcut Connection(x)を導入することで実現しています。Bottleneckアーキテクチャと呼ばれます。
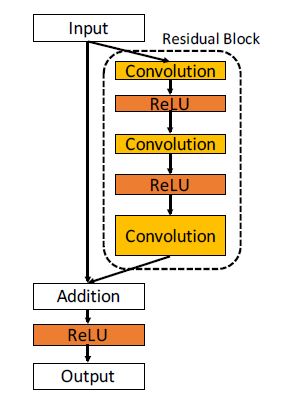
Bottleneckアーキテクチャは、畳込み層(残差ブロック)とSkip Connectionの組み合わせになっていて、それぞれの要素を足し合わせる構造になっています。
残差ブロックを導入することで、結果的に層の深度の限界を押し上げることができ、精度向上を果たすことが出来きます。
以上がResnetの紹介になります。
Fully convolutional networks(FCN)について
Daniil Pakhomovらが報告しているネットワークは、Resnetの全結合層を1×1の畳み込み層に置き換えています。
このように全結合層を持たず、ネットワークが畳み込み層のみで構成されているネットワークを Fully convolutional networks(FCN)と言います。
全結合層を無くすことで、従来の畳み込みニューラルネットワーク(ResnetやVGG-16など)のように入力画像のサイズを固定する制約がなくなります。
また全結合層を畳み込み層に置き換えると、クラス分類の結果を1ピクセルごとに出力できるようになります。
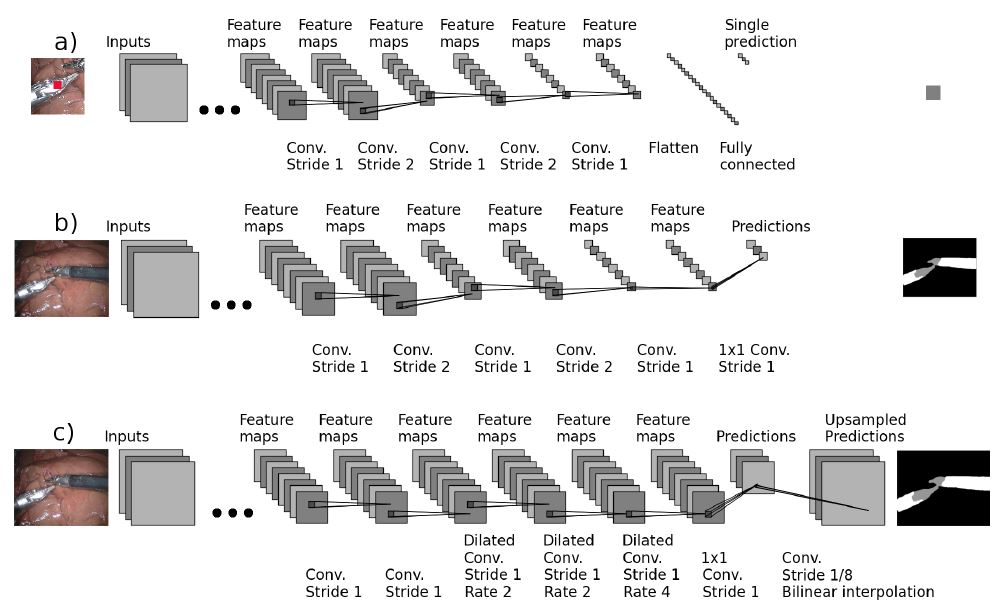
下図のFig.2(a)は、従来のResnetやVGGなどのCNNのネットワーク図です。
Fig.2(b)は、Fig.2(a)のCNNに対して、全結合層を1×1の畳み込み層に置き換えた図になります。
Dilated Convolutionsについて
Daniil Pakhomovらが報告しているネットワークは、Dilated Convolutionを適用しています。
Dilated Convolutionとは、フィルターとの積を取る相手の間隔(Dilation_rate)をあける畳み込みのことです。
Dilation_rateを大きくしていけばpoolingを使用せず、小さなフィルターサイズで長距離の畳み込みが可能になります。
poolingを使わないため、画像をダウンサンプリングする必要が無くなります。
上図のFig.2(c)は、 Fig.2(b)でFCNを適用したネットワークに対して、さらにDilated Convolutionを適用したネットワークです。
畳み込み層では、一度もダウンサンプリングを行わず、推論値を出力しています。
また推論値からバイリニア補間によってアップサンプリングを行うことで、入力画像サイズでのセグメンテーション結果を出力しています。
「ロボット手術における器具セグメンテーション」コード編
実際に手術器具セグメンテーションで用いているコードについて解説していきます。 Daniil Pakhomovらがいくつかモデルを評価している中で、ネットワークの深さ101層のResnet-101を用いたコードについて紹介します。
下記のステップに分けて解説します。
ステップⅠ: 画像色情報の標準化
ステップⅡ: アップサンプリングフィルタ係数算出
ステップⅢ: ニューラルネットワーク(Resnet-101)の定義
ステップⅣ: アップサンプリングサイズ算出、実行
ステップⅤ: 各ブロック層の特徴量出力
ステップⅠ: 画像色情報の標準化
まず入力画像について、各ピクセルデータから各RGB平均値を引き、画像色情報の標準化を行います。
with tf.variable_scope("resnet_v1_101_16s") as resnet_v1_101_16s:
upsample_factor = 16
# Convert image to float32 before subtracting the
# mean pixel value
image_batch_float = tf.to_float(image_batch_tensor)
# Subtract the mean pixel value from each pixel
mean_centered_image_batch = image_batch_float -
[_R_MEAN, _G_MEAN, _B_MEAN]
なおピクセルデータは浮動小数点型に変換します。
ステップⅡ: アップサンプリングフィルタ係数算出
アップサンプリングを行う際のフィルタ係数を算出します。
ステップⅠでupsample_factor:16としているため、生成されるフィルタサイズは、32×32のフィルタ係数が生成されます。
upsample_filter_np = bilinear_upsample_weights
(upsample_factor,number_of_classes)
upsample_filter_tensor = tf.constant(upsample_filter_np)
ステップⅢ: ニューラルネットワーク(Resnet-101)の定義
ネットワークモデル(Resnet-101)を定義します。
with slim.arg_scope(resnet_v1.resnet_arg_scope()):
logits, end_points = resnet_v1.resnet_v1_101
(mean_centered_image_batch, number_of_classes,
is_training=is_training, global_pool=False,
output_stride=16)
downsampled_logits_shape = tf.shape(logits)
ネットワークモデルは、tensorflowパッケージに含まれている resnet_v1_101モジュールを使用します。
Resnet内の各ブロック層のテンソルサイズを取得できるようログ出力を設定します。
ステップⅣ: アップサンプリングサイズ算出、実行
ステップⅢで実施した各ブロック層のテンソルサイズから、アップサンプリングサイズを算出します。
算出した アップサンプリングサイズ、ステップⅡで求めたフィルタ係数をconv2d_transposeモジュールに入力し、アップサンプリングを行います。
# Calculate the ouput size of the upsampled tensor
upsampled_logits_shape = tf.pack([downsampled_logits_shape[0],
downsampled_logits_shape[1] * upsample_factor,
downsampled_logits_shape[2] * upsample_factor,
downsampled_logits_shape[3]])
# Perform the upsampling
upsampled_logits = tf.nn.conv2d_transpose(logits,
upsample_filter_tensor,
output_shape=upsampled_logits_shape,
strides=[1, upsample_factor, upsample_factor, 1])
ステップⅤ: 各ブロック層の特徴量出力
ネットワークの各ブロック層における特徴量を取得できるようにします。
# Map the original vgg-16 variable names
# to the variables in our model. This is done
# to make it possible to use assign_from_checkpoint_fn()
# while providing this mapping.
resnet_v1_101_16s_variables_mapping = {}
resnet_v1_101_16s_variables = slim.get_variables(resnet_v1_101_16s)
for variable in resnet_v1_101_16s_variables:
# Here we remove the part of a name of the variable
# that is responsible for the current variable scope
original_resnet_v1_101_checkpoint_string = variable.name[len
(resnet_v1_101_16s.original_name_scope):-2]
resnet_v1_101_16s_variables_mapping
[original_resnet_v1_101_checkpoint_string] = variable
return upsampled_logits, resnet_v1_101_16s_variables_mapping
get_variablesから各ブロック層の結果を取得します。
resnet_v1_101_16s_variables_mappingに、ブロック名とその特徴量(テンソル)が格納されます。
最後に戻り値として、推論結果と、各ブロックの特徴量を返しています。
以上が Resnet-101についてのコード解説になります。
評価結果
Daniil Pakhomovらは、評価データにMICCAI内視鏡ビジョンチャレンジで採用されたデータセットを使用しています。
このデータセットは、45秒程度の縫合用のニードルドライバーの映像で構成されています。
Fig.3に示しているのが、 Resnetをベースとした本手法によるバイナリセグメンテーションと、マルチクラスセグメンテーションの結果です。
(a)と(c)はデータセットの元データです。
(b)は、(a)の画像におけるバイナリセグメンテーションの結果です。
(d)は、(c)の画像におけるマルチクラスセグメンテーションの結果です。
(b)の結果は器具全体を一つのドライバーとして分類しているのに対して、(d)の結果は、器具のニードル部分とそれ以外の部分で分類できていることがわかります。

セグメンテーションの評価指標は、Daniil Pakhomovらは Intersection Over Union(IoU)を使用しています。
IoUは、正解領域に対して予測領域が重なる割合を示しています。
数値が高いほど、正確な領域であることを表します。
Fig.4に示すのバイナリセグメンテーションのIoUです。
Daniil Pakhomovらの手法は、従来手法の一つであるFCNよりも約4%程IoUが改善していることがわかります。
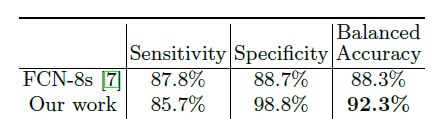
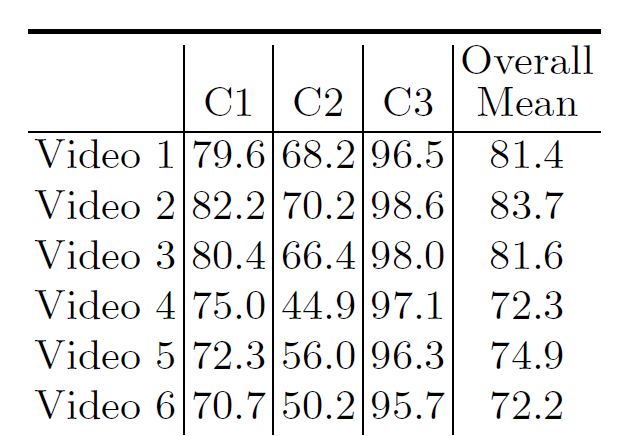
続いてFig.5に示すのがマルチクラスセグメンテーションのIoUです。
平均して7割程度の分類精度であることがわかります。
一部の映像では5割に満たない状況もあるため、手術ロボットの性能としては、まだ改善の余地があると思われます。
以上が残差学習(Resnet)を用いた手術器具セグメンテーションのコード解説です。
次回は、手術器具セグメンテーションのデモ紹介を行っていきます!
関連記事
【AI実装コード解説】「産業の排出煙を認識」(前編)物体認識レクチャー#1
【AI実装コード解説】「産業の排出煙を認識」(後編)物体認識レクチャー#2
【悲報】低所得世帯の物体認識AIは精度が低いらしい(AI×社会)【論文】
「セグメンテーション」とは?意味をサクっと解説!【AI用語集】
アリババ、文書画像の文字をラベリングするためのAI学習ツールを公開【GitHub】
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP