
コンピュータビジョンの分野において最も権威ある学会の一つであるCVPRで発表された中から「動画」についての研究を紹介します。
「動画×AIの最先端にキャッチアップしておきたい」
「トップ学会CVPR2020の論文には関心があるが、数が多すぎてどれを読めばいいかわからない」
「画像認識技術を仕事で使うので注目度の高い論文に触れておきたい」
「そもそもCVPRって何?」
こんな方は、ぜひ参考にしてみてください!

そもそもCVPRとは?
CVPRの正式名称は「Computer Vision and Pattern Recognition(コンピュータビジョンとパターン認識)」です。Compuer Visionというのはロボット(コンピュータ)の視覚を指します。画像処理、映像処理の技術分野全般を指すことが多いです。
そのComputer Visionの分野において最も権威ある学会の一つがこのCVPR。近年ではComputer Vision分野でDeep Learningを使う事が当たり前になってきているので、CVPRはDeep Learningに関するトップカンファレンスの一つだとも言われています。
第1回目では「3D」、第2回目では「GAN」という軸でそれぞれ論文をピックアップしました。第3回目の今回は、「動画」に関する論文に注目していきます。
■第1回:【CVPR2020】「3D」に関するAI論文5選
■第2回:【CVPR2020】「GAN」に関するAI論文5選
「動画」の論文5つPICKUP
CVPR 2020では、5865本の論文が投稿され、そのうちacceptされたのが1467本の論文でした。そのうち、動画関連の論文は104件でした。
この中から、特に興味深いおすすめの5本を紹介します。じっくり読む論文を選ぶ際のヒントにしていただけると幸いです。
1本目. Understanding Road Layout From Videos as a Whole
2本目. Sideways: Depth-Parallel Training of Video Models
3本目. Video Object Grounding Using Semantic Roles in Language Description
4本目. Action Modifiers: Learning From Adverbs in Instructional Videos
5本目. Clean-Label Backdoor Attacks on Video Recognition Models
1本目:車窓から道路の形を予測する
自動運転の実現のためには様々な技術が必要です。中でも、視覚を担うイメージセンシングのソフト面での進歩はかかせません。
タイトル:Understanding Road Layout From Videos as a Whole(PDF)
著者:Buyu Liu, Bingbing Zhuang, Samuel Schulter, Pan Ji, Manmohan Chandraker
機関・国:NEC Laboratories America、アメリカ
課題設定のポイント
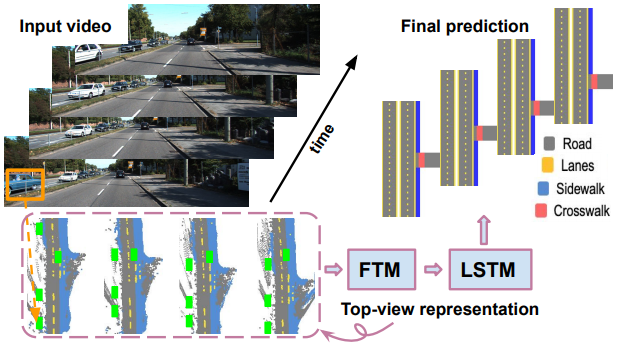
この論文では、ビデオシーケンスから複雑な道路シーンのレイアウトを推定する問題を扱います。車から見た道路動画像を入力として、上から見た道路画像、道路情報を生成します。
アプローチ・結果の面白さ
動画中のカメラの動きを活用し、コンテキストキューを含む、長期的な動画情報を組み込みます。具体的には、動画中の予測の一貫性を持たせることを目的としたモデルを導入します。モデルはLSTMと特徴変換モジュール(FTM)から構成されています。前者は隠れた状態を持つ一貫性制約を暗黙的に組み込み、後者は映像に沿った情報を集約する際にカメラの動きを明示的に考慮します。さらに、物体などの道路関係者をモデルに導入することで、コンテキスト情報を組み込みます。
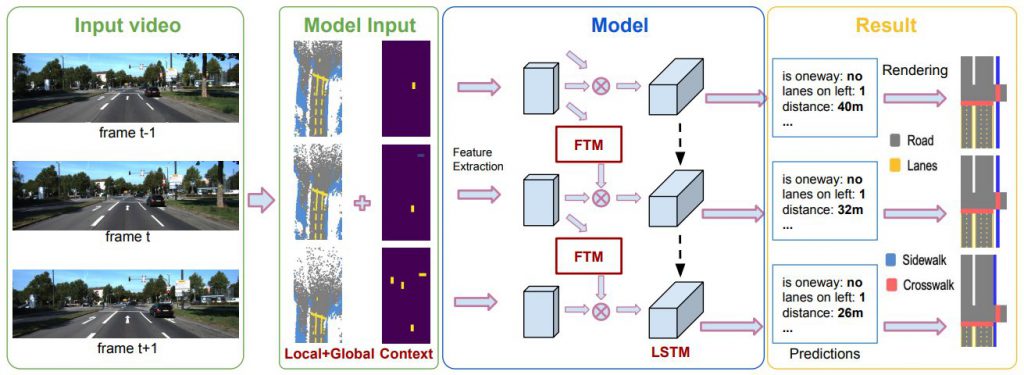
2つのデータセットを用いた実験では、以下のことがわかりました。
(1) グローバルな手がかりとコンテキストな手がかりのどちらかを組み込むことで予測精度が向上し、両方を利用することで最高のパフォーマンスが得られます。
(2)LSTMモジュールとFTMモジュールを導入することで、動画の予測精度が向上します。
(3) 提案手法はSOTAを大きく上回る性能を示しました。
2本目:DeepMindによる動画学習のための新手法
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP