
■お知らせ:AIDBの感想を募集しています!
テニスの「ファーストサーブ成功率」は勝率に関係あるの?データで確かめてみた
こんにちは。松本(@tennisahko)です。
この記事では、テニスのサーブはどのくらい大事なのか?というテーマについて、機械学習を使って実際に分析してみたいと思います。

テニス界の通説をデータ分析で検証!
僕は福岡大学4年生で、統計専攻でデータ分析を学んでいます。テニス歴は約10年で、文部科学大臣杯(愛好会の全国大会)で優勝経験があります。
幼少期の頃からテニスを始め、今でも続けているのですが、テニスクラブでは「ファーストサーブを70%入れないと勝てないぞ」と言われていました。実際にデータは見たことないのですが、経験上は70%でなくても勝てると感じていたので、この通説の真偽をデータで確かめてみることにしました。
準備するもの
データセット
ATPシングルスの試合結果データ1877-2017年までのデータ(約10万試合分)を用意しました。
※ATPとは、世界男子プロテニス協会のこと
モデル
今回は決定木分析(sklearnライブラリのDecisionTreeClassifier)を使いました。
環境
GoogleColaboratoryを使いました。色々なライブラリが搭載されており、サーバーの構築が不要なのでいきなり分析を始めることができます。(pip listで全てのライブラリのバージョンが確認できます。)
サーバースペック
Qiitaの記事を参考に、以下の環境で実施しました。
・n1-highmem-2 instance
・Ubuntu 18.04
・2vCPU @ 2.2GHz
・13GB RAM
・(GPUなし/ TPU)40GB, (GPUあり)360GB Storage
・GPU NVIDIA Tesla K80 12GB
・アイドル状態が90分続くと停止
・連続使用は最大12時間
・Notebookサイズは最大20MB
データの前処理
まず、取り扱う対象となるデータを整理します。
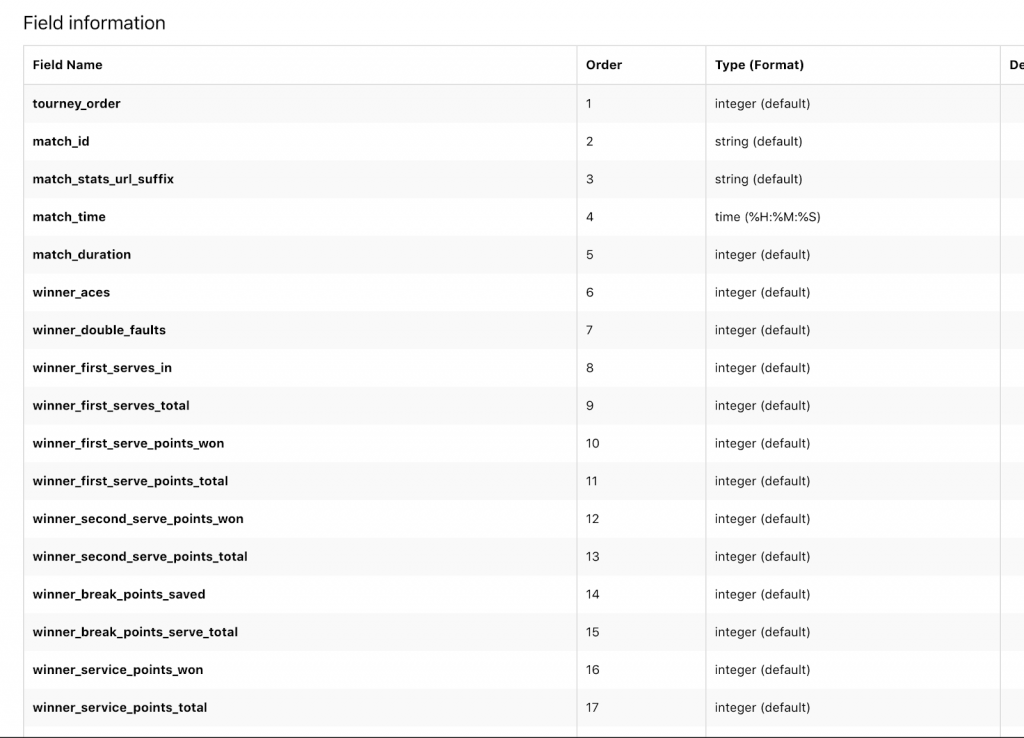
今回のデータは、1レコードが1試合で、勝者と敗者のデータが1行になってしまっていたので、まずはカラム名を統合することによって1レコードを1プレイヤーに処理しました(winner_acesとloser_aces→acesのように)。この処理をしないと勝者と敗者のフラグを立てることができないからです。
さらに、データは、試合数が長引けば長引くほど数字は増えるので、すべてカウント数を率に修正しました。
また、欠損値を含んでいる行はすべてて捨てました。結果として、元の列から以下のような列にデータを作り替えました。

これらのデータを用いて、テニスクラブで言われていた「ファーストサーブが入る確率」が勝者と敗者でどう違うのかヒストグラムでプロットします。
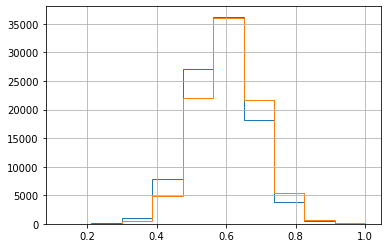
グラフを見た所、あまり変わりません。
今度は「ファーストサーブの確率」の平均を見てみます。

こちらもほとんど変わりません。
これは…「ファーストサーブの確率」はあまり関係ないのでは!?
主成分分析
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP