
■お知らせ:AIDBの感想を募集しています!
心臓病の新しい見つけ方。データ・マイニングとランダムフォレスト【AI論文】
(Featured AI and healthcare) A new way to find heart disease. Data mining – Random Forest (Publication)
[論文] H. B. F. David and S. A. Belcy, “HEART DISEASE PREDICTION USING DATA MINING TECHNIQUES”. ICTACT Journal on Soft Computing, 9 (1), 1817-1823 (2018). [DOI: https://doi.org/10.21917/ijsc.2018.0253 –http://ictactjournals.in/ArticleDetails.aspx?id=3621]
3つの要点
✔️異常がある人とない人とを分類するのに適したアルゴリズムを見つけることが目的。
✔️使ったデータはUCIレポジトリから取ってきたもの。
✔️ランダムフォレストが81%の精度で最良の結果を出した。
概説
マイニングは、統計解析、機械学習、データベース技術からの組合せ戦略を用いて隠れパターンを抽出するために大規模データベース上で実行される技術だ。
さらに,医療データのマイニングは,盛り上がっている医療分野における様々な応用開発の重要性から,非常に重要な研究分野である。
世界中で起こっている死亡をまとめると、心臓病が主な原因のようだ。人が心臓病を持つ可能性を決めることは、長年の経験と集中的な医学検査を必要とするため、医師にとって複雑な仕事である。
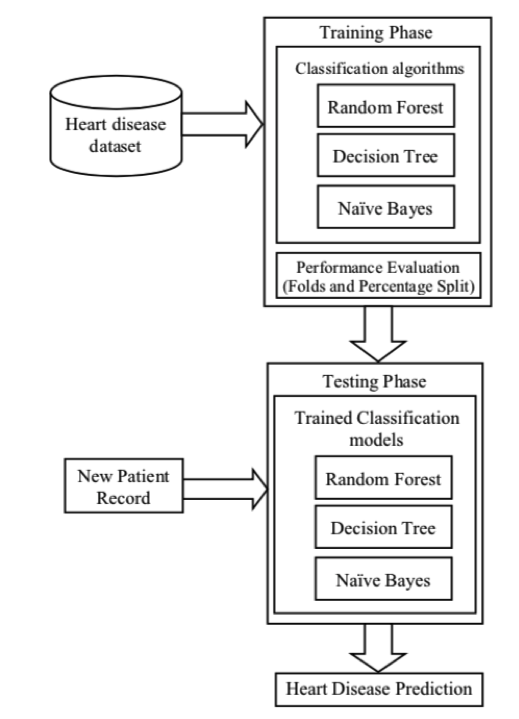
本研究では、ランダムフォレスト、決定木および単純ベイズといった3つのデータマイニング分類アルゴリズムが取り扱われ、心臓病の可能性を分析し予測するための予測システムを開発するために使われた。
この重要な研究の主な目的は、正常な人と異常をもつ人の分類を行う場合に最大の精度を提供するのに適した最良の分類アルゴリズムをみつけることだ。
従って、早期の人命損失の防止が可能となる。
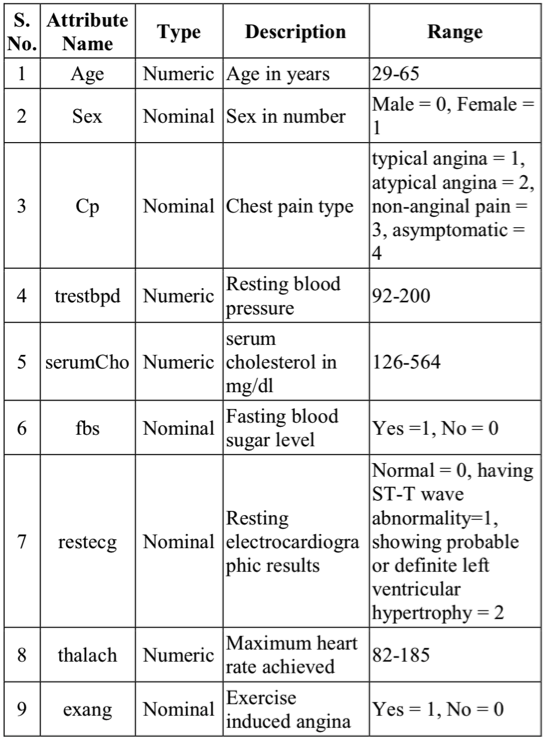
UCI機械学習リポジトリ(表1)の心臓病ベンチマークデータセットの助けを借りて,アルゴリズムの性能評価のための実験の仕組み(図1)を作った。
ランダムフォレストが心臓病予測のための他のアルゴリズムと比較(表2,3)した際に、81%の精度と最良の性能を示すことが分かった。
著者
Benjamin Fredrick David (Manonmaniam Sundaranar University, India)
S Antony Belcy (Manonmaniam Sundaranar University, India)
出版情報
Published: October 2018
Open Access This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP