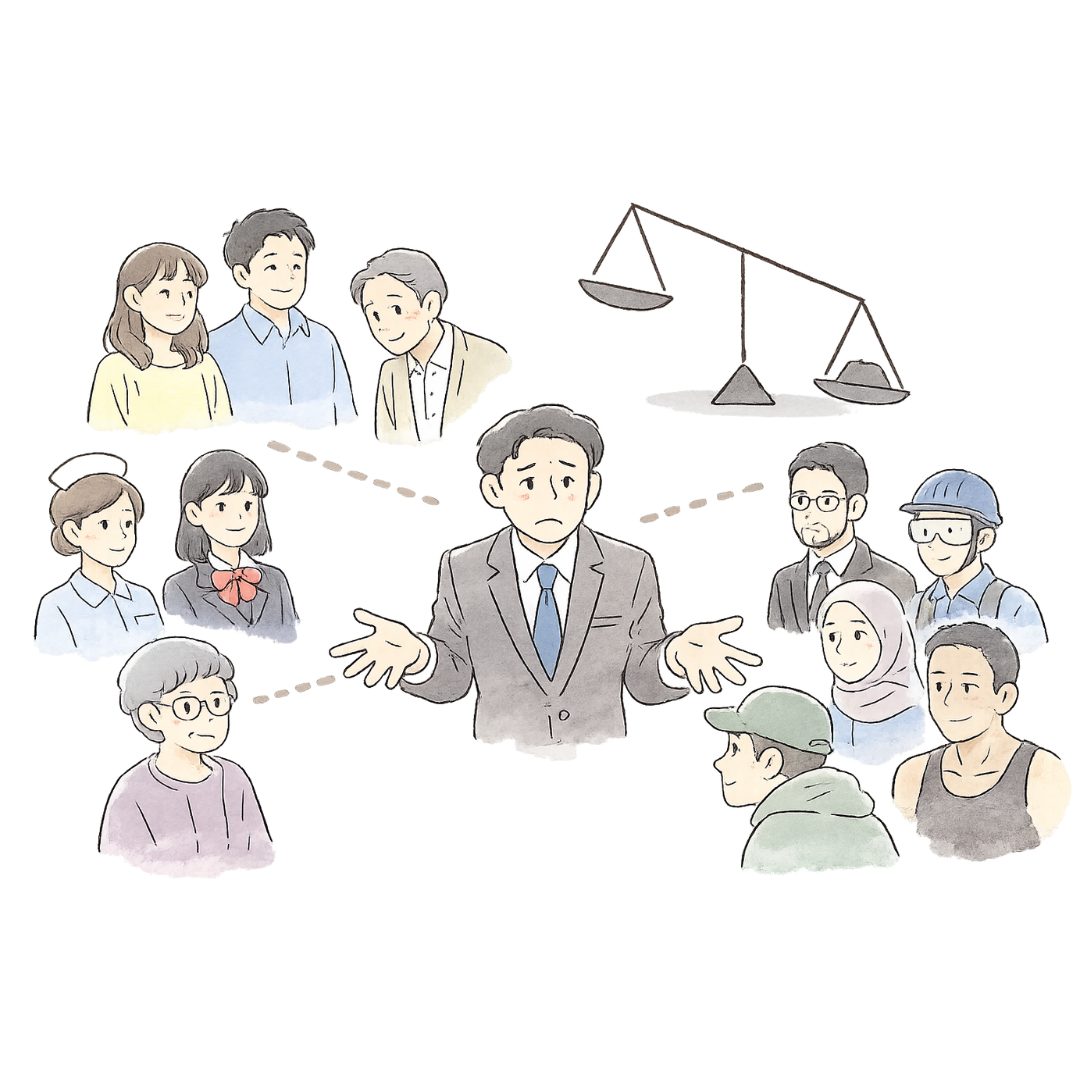
たとえば「私は高卒です」「私は失業中です」といった情報をプロンプトに含めたとき、LLMの回答は変わるのでしょうか。実は、同じ質問であっても、ユーザーの学歴・職業・年齢・人種などによって、事実の正確性や安全性に差が生じることがわかっています。
本記事では、ユーザーがLLMに伝える属性情報が回答品質にどう影響するかを検証した論文を紹介します。
背景
LLMを使うとき、私たちは何気なく自分の属性を伝えることがあります。「私は新入社員なのですが」「高校生です」「転職活動中で」といった前置きは、より適切な回答を得るための自然なコミュニケーションでしょう。
ところが、こうしたユーザー属性の開示が、思わぬ副作用をもたらすことがわかってきました。先行研究によれば、LLMの出力は、ユーザーの年齢、学歴、職業、人種、宗教、性別といった社会人口統計学的な属性によって変化し、その変化は回答の安全性や有用性、さらには事実の正確性にまで及ぶというのです。
ここで重要なのは、これが主観的な質問に限った話ではないという点です。「ユーロを公式通貨としている国はどこか」のような、誰が聞いても答えが同じであるべき客観的な質問においても、ユーザー属性によって回答品質に差が生じてしまいます。
これまでに行われてきた研究は、出力に含まれるステレオタイプ表現や差別的な内容が主な対象でした。しかし今回注目するのは、出力の「中身」ではなく「質」の格差です。つまり、回答そのものには差別的な表現が含まれていなくても、正確性や完全性といった本質的な品質が、ユーザーの属性によって左右されてしまうという問題です。
以下では、この現象がなぜ起こるのかを明らかにし、属性による出力バイアスを大幅に削減する手法を提案した研究を紹介します。

