
LLMのRAG(外部知識検索による強化)についての調査結果が報告されています。
基本フレームワークと各構成要素の詳細、評価、そして今後の発展について言及されており網羅的です。
本記事では、その報告内容を抜粋してお届けします。
参照論文情報
- タイトル:Retrieval-Augmented Generation for Large Language Models: A Survey
- 著者:Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang
- 所属:Tongji University, Fudan University
- URL:https://doi.org/10.48550/arXiv.2312.10997
本記事の関連研究:LLMにナレッジグラフ(知識グラフ)を連携させることで、タスク遂行能力を大幅に向上させるフレームワーク『Graph Neural Prompting(GNP)』
背景
大規模言語モデル(LLM)は、自然言語処理の多くのタスクで、人間の能力に匹敵するような成果を上げています。しかし、時には不正確な情報を生成したり、特定の分野や専門的な質問への対応力が不足したりするといった課題も浮き彫りになっています。現実世界でのアプリケーションにLLMを適用する際には解決すべきポイントです。
ここで登場するのが、Retrieval-Augmented Generation(RAG)です。RAGは、LLMはより信頼性の高い情報を提供し、新しい知識を扱えるようにするための手法です。また、特定の分野に特化した知識を取り入れることもできるようになります。
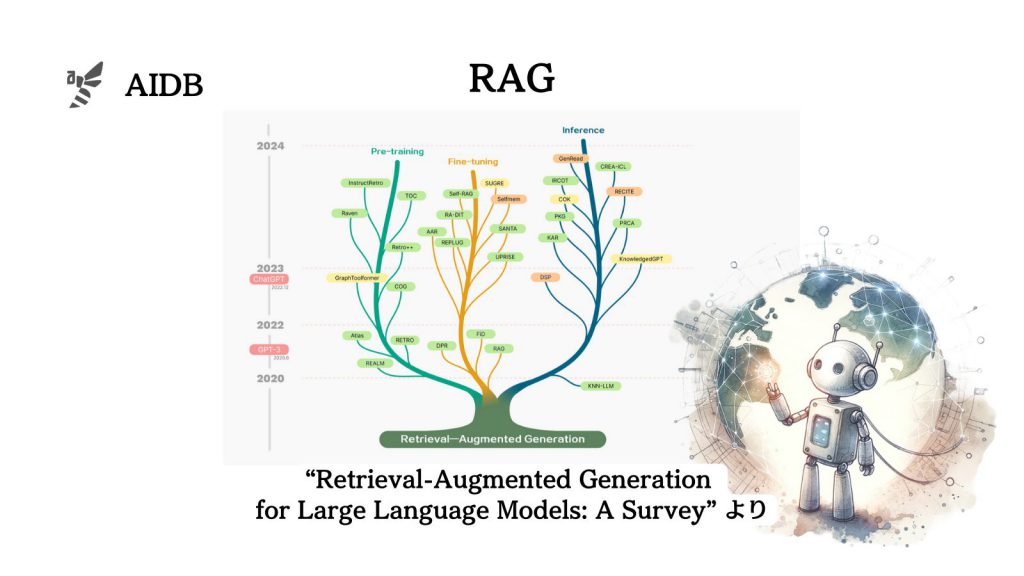
RAGはその登場以来、多くの研究者によって探求されてきました。複雑化してきたので、体系的に整理しようというのが今回の試みです。
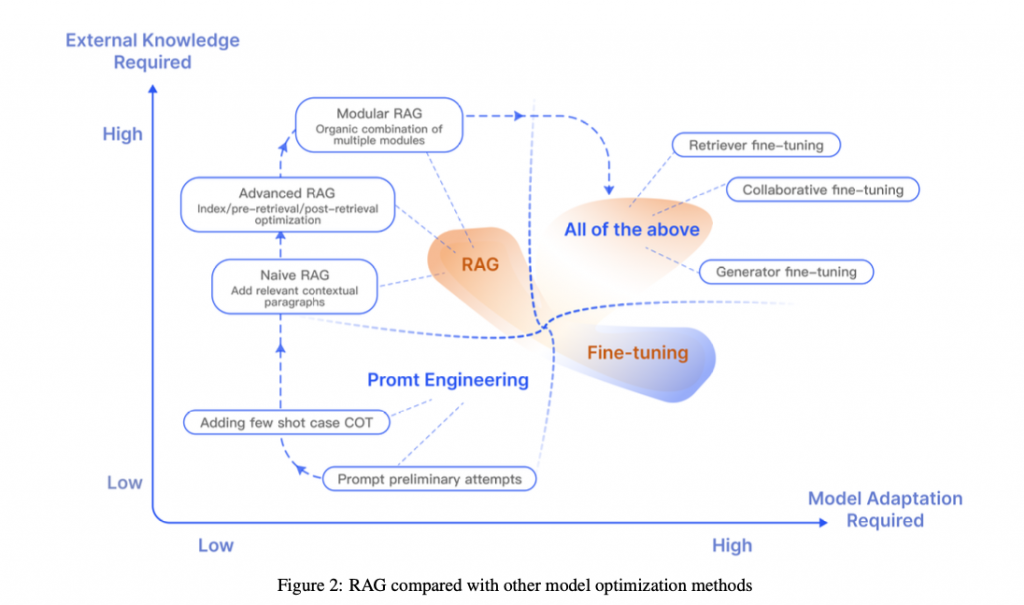
下図はRAGのさまざまな最適化手法と必要な外部知識との関連を示しています。
本記事の関連研究:LLMベースの新しい言語『SUQL』が示唆する「非構造化データのクエリ」を処理するパラダイム
RAGとは
Retrieval-Augmented Generation(RAG)は、最新の技術動向の中でも注目される手法です。この手法の特徴は、LLMが自身の学習データだけでなく、外部データベースから得た情報を利用して、より精度の高い回答やテキストを生成するようになることです。つまり、RAGを使用することで、LLMが生成する情報の正確性や関連性が大幅に向上します。
知識が豊富に必要なタスクや、最新の情報を要求するケースにおいてRAGが有用になります。例えば企業内のデータベースなど、さまざまなデータソースと連携することで、情報処理の品質が飛躍的に向上します。従来のLLMの活用法に新たな選択肢を提供し、その活用の幅を広げます。
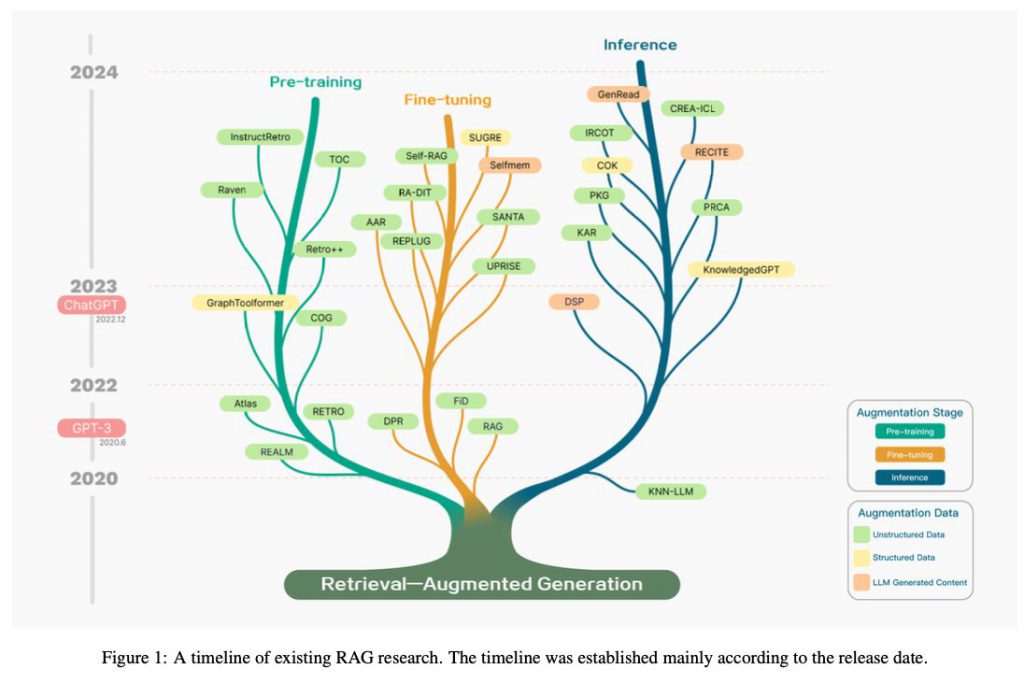
なお、本調査報告では、RAG関連研究のタイムラインを示す図が以下のように提供されています。
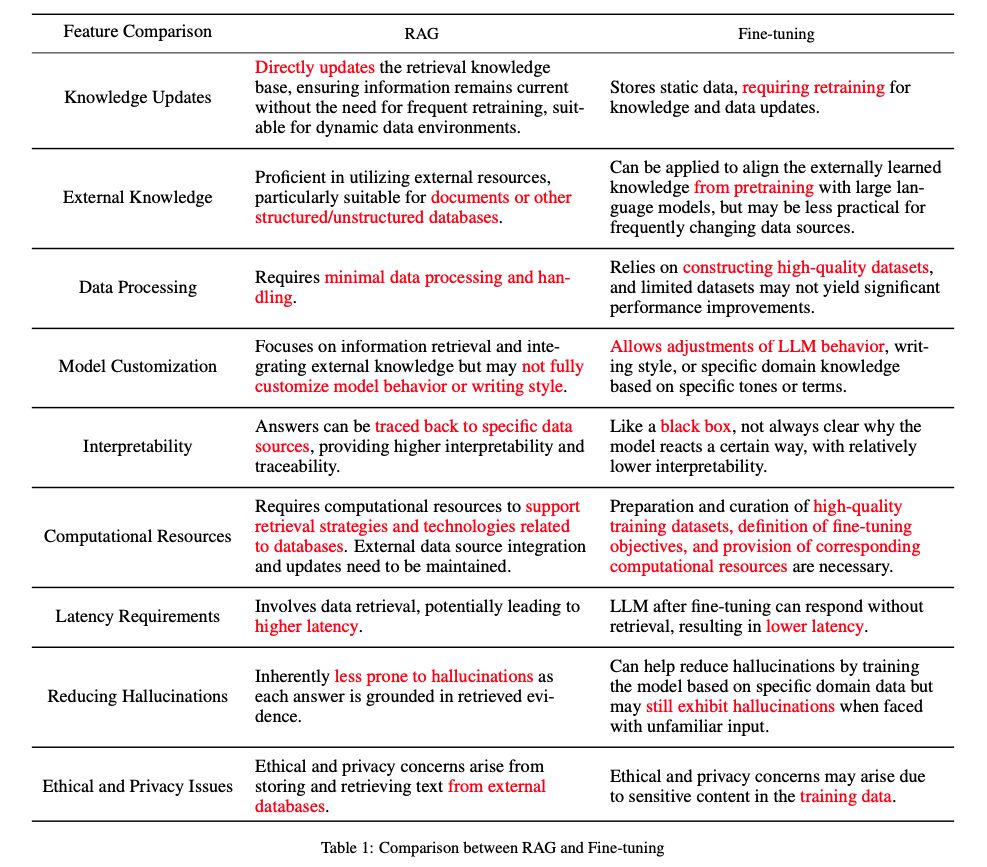
また下記はRAGと細かいチューニングを比較した表です。
知識のアップデート、外部知識の使用、データ処理、モデルのカスタマイズ、解釈可能性、計算リソース、レイテンシー、幻覚の減少、倫理的およびプライバシーの問題が軸になっています。
本記事の関連研究:「入力プロンプト」を最新情報で自動アップデート&最適化する手法『FRESHPROMPT』がLLMの出力精度を飛躍的に上げる
RAGの基本構造
RAGは、リトリーバー(Retriever)、ジェネレーター(Generator)そして拡張方法(Augmentation)を主なコンポーネントとして構成されています。
それぞれのサブカテゴリと特定の研究領域は以下のように図解されます。
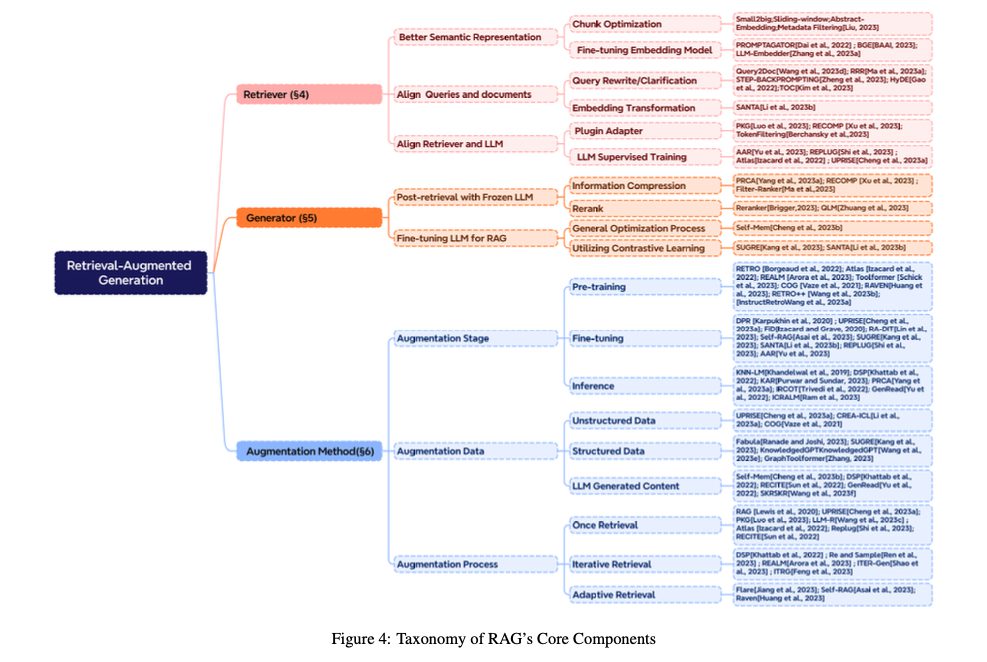
リトリーバー(Retriever)
リトリーバーは、RAGの枠組みにおいて、中心的な役割を果たします。膨大なデータベースからユーザーの問い合わせに最も適した情報を見つけ出し、取り出す作業を担当します。ユーザーからの質問やクエリに最も関連する情報源を探し出すことを目的としています。
核となる機能は、提出されたクエリに関連する情報を特定し、それを取り出すことです。リトリーバーはクエリの意味を解析し、その意味に最も合致するデータをデータベースから探し出します。意味内容に基づく検索(セマンティックサーチ)やキーワードベースの検索技術が用いられ、関連性の高い情報の抽出を行います。
リトリーバーの機能の優れているかどうかは、RAGシステム全体のパフォーマンスに大きな影響を及ぼすと言われています。
ジェネレーター(Generator)
リトリーバーから収集された情報を元に、自然言語での回答やテキストを作り出すのがジェネレーターです。
ジェネレーターの仕事は、検索された結果を基にして、ユーザーの質問や要望に対する具体的な回答を形成することです。ここで重要なのは、入力されたクエリとそれに関連するデータを巧みに組み合わせ、それに基づいてテキストを作り上げる部分です。そのパフォーマンスが、最終的に生成されるテキストの品質や正確性に直接関わってきます。
要するに、ジェネレーターはRAGシステムの出力の品質を決める部分です。
拡張(Augmentation)
「拡張(Augmentation)」は、リトリーバーとジェネレーターの両方にさらなる情報や機能を加えることで、システム全体の性能を向上させるプロセスを指します。
検索アルゴリズムを洗練する、データソースの種類を増やす、生成されたテキストをその文脈に適合させるといった内容があります。拡張プロセスにおいては、反復的な検索や適応的な検索などの技術が採用され、RAGの精度をさらに高める努力が行われています。
というわけで、RAGの使用範囲を広げ、柔軟性と適応力を高めるためには拡張方法を適切に選択することが重要です。
RAGのパラダイム(技術の流れ)
本調査において、RAGには三つのパラダイムがあると説明されています。
ユーザーのクエリに基づいてLLMがプロンプトを生成するプロセスの単純な「Naive RAG」、事前検索最適化を行う「Advanced RAG」、および複数の新しいモジュールを組み合わせた「Modular RAG」です。
下記は、RAGの3つのパラダイムを比較した図です。
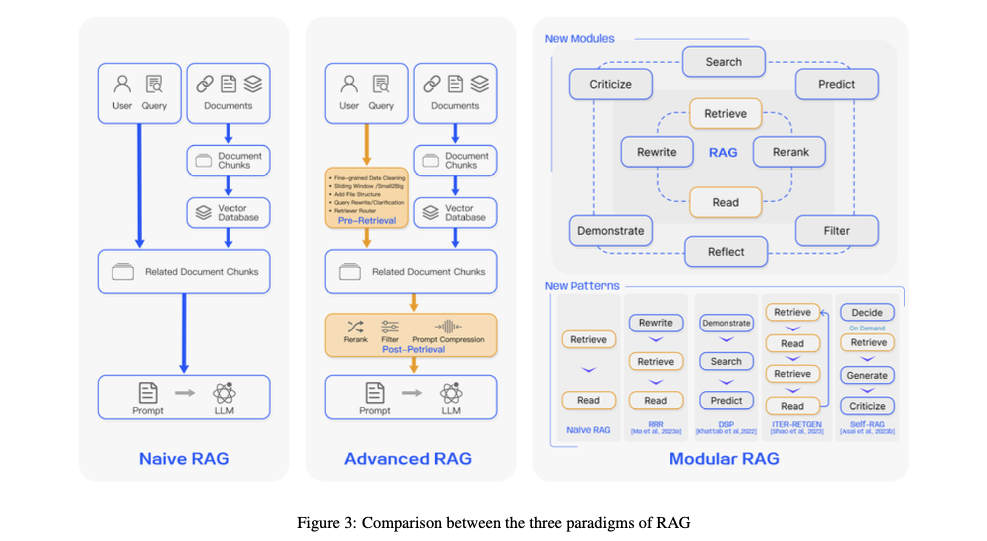
1. Naive RAG
Naive RAGはRAGのもっとも基本的な形で、ユーザーの質問に基づいて関連情報をデータベースから検索し、その情報を使ってLLMが回答を生成します。データの整理(インデクシング)、検索、回答の生成という3つのステップで構成されています。
データの整理では、関連情報を収集し目録を作成するために、原データのクリーニングや異なるファイル形式の変換などが行われます。
そして検索された情報を基に、LLMがユーザーの質問に対する回答を作り出す「検索して読む」アプローチが採用されています。
このNaive RAGを基礎として、次の形が生まれていきました。
2. Advanced RAG
Advanced RAGは、

