
Microsoftの研究チームは、従来の大規模言語モデル(LLM)への入力プロンプトを効率的に圧縮し、意味そのものは維持する技術『LLMLingua』を開発しました。
本技術は、長いプロンプトによってLLMの応答速度が遅延したりコストが高くなったりしてしまう問題に対処するものです。
実施された実験では、LLMLinguaが他の手法に比べて優れた性能を示し、さまざまなタスクにおいてもその効果が確認されました。
本記事では詳細を見ていきます。
参照論文情報
- タイトル:LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
- 著者:Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu
- 所属:Microsoft
- URL:https://doi.org/10.48550/arXiv.2310.05736
- GitHub:https://github.com/microsoft/LLMLingua
本記事の関連研究:LLMZip:大規模言語モデルがテキスト圧縮の新境地を開く
研究の背景
LLMに与えられるプロンプトは、長くなりがちです。時には数千、場合によっては数万のトークンにまで及ぶことがあります。プロンプトが長いと、モデルの推論速度の遅延を引き起こし、コストが増加する原因にもなります。
チェーンオブソート(CoT)やインコンテキスト学習(ICL)など、プロンプト手法が探求されるにつれて、ますます多くの情報をプロンプトに含める状況になっているのも理由の一つです。
このような問題を解決するため、世の研究者たちや技術者たちは、プロンプトを効率的に圧縮する方法を探っています。今回、Microsoftの研究者らによって開発された「LLMLingua」は、そんなプロンプト圧縮の最新手法です。
本記事の関連研究:ChatGPTの効果的なプロンプト手法における「基本のキ」を理論とテンプレート両方で紹介
LLMLinguaの主要なポイント
以下にLLMLinguaの主な特徴を並べます。
1. 重要な情報を保持する
LLMLinguaは、プロンプト圧縮時に重要な情報を損なうことなく、セマンティックな一貫性を維持することに重点を置いています。後述する「予算コントローラー」というコンポーネントが重要な役割を果たしています。
2. LLMの推論速度が向上する
小規模モデルを使用して効率よく情報を圧縮し、大規模モデルとの間にある分布のギャップに対処することで、LLMの推論速度の向上を実現するとのことです。
計算プロセスを増大させることなく、効果的な情報の維持を行います。
3. 計算コストが削減される
圧縮されたプロンプトは、元のプロンプトに含まれる推論情報を効果的に保持し、たとえ圧縮率が14倍や20倍に達しても、パフォーマンスのわずかな低下のみで計算コストを抑えることができるとされています。
本記事の関連研究:基盤モデル(GPT-4)はプロンプトの工夫で専門特化モデルに匹敵するほど性能が向上することが「医学分野」で示唆される
LLMLinguaのフレームワーク
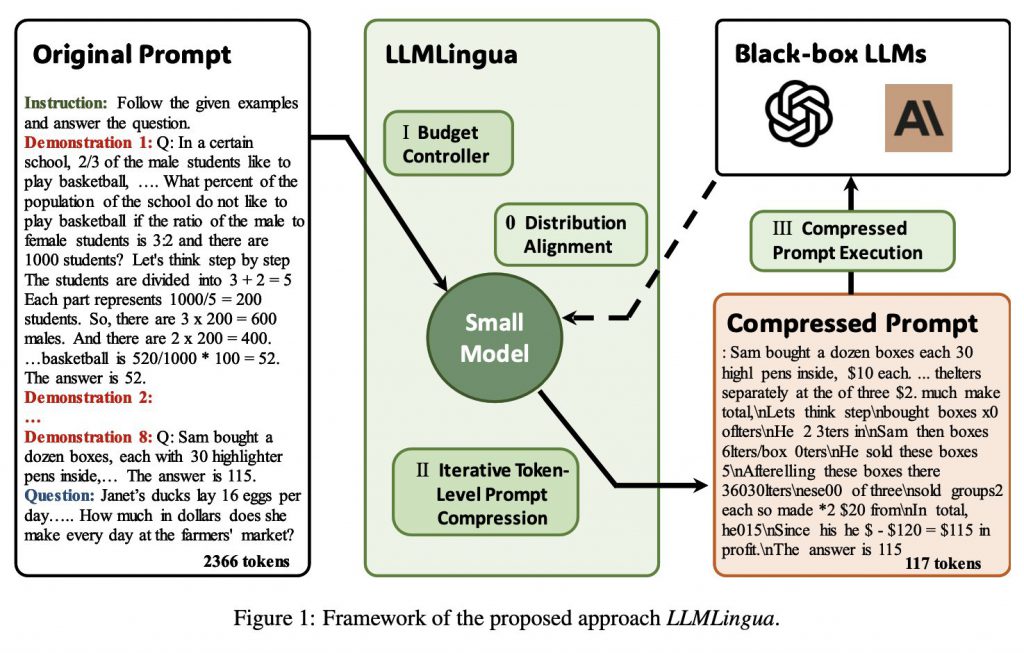
1. 大雑把な圧縮とトークンレベルでの圧縮の組み合わせ
圧縮プロセスには、2つの異なるステージがあります。
まず、

