
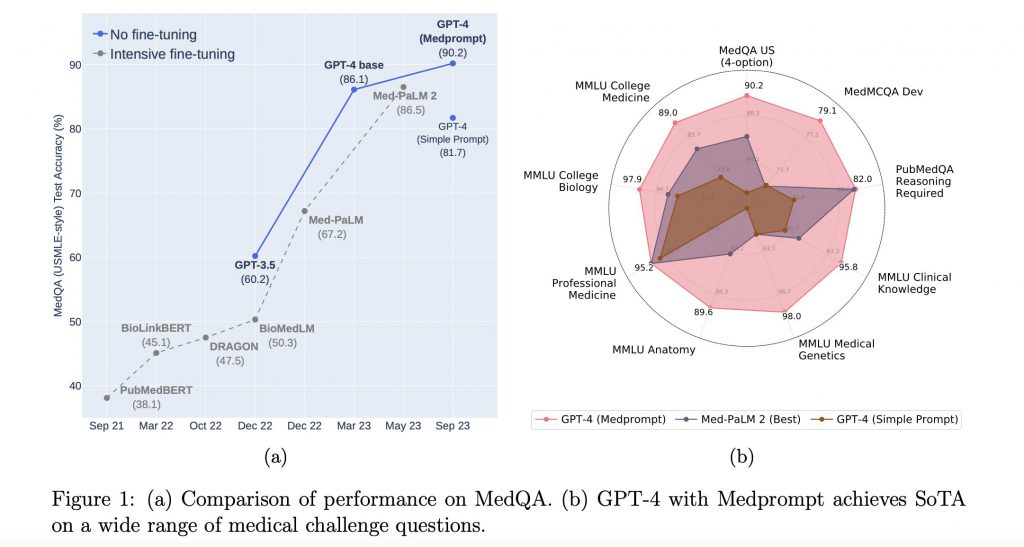
OpenAIの開発したGPT-4などの基盤モデルは、多様なタスクにおいて高い能力を発揮しています。一方で深い専門知識が試される領域においては、専門知識でトレーニングされた特化型モデルと比較して、汎用モデルの性能は劣るだろうと考えられてきました。しかし、Microsoftの研究者たちが最近行った実験によると、その前提には一考の余地がありそうです。
研究では、医学分野において、特殊なトレーニングを施されていない(と考えられている)GPT-4が、プロンプトの工夫を通して、専門モデルと同等あるいはそれ以上の成績を収めることが示唆されました。研究結果は、単に基盤モデルの性能を評価するだけでなく、プロンプトの工夫がAIの能力をいかに引き出すかという視点を提供しています。
本記事では実験結果を中心に報告内容を見ていきます。


参照論文情報
- タイトル:Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
- 著者:Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, Renqian Luo, Scott Mayer McKinney, Robert Osazuwa Ness, Hoifung Poon, Tao Qin, Naoto Usuyama, Chris White, Eric Horvitz
- 所属:Microsoft
- URL:https://doi.org/10.48550/arXiv.2311.16452
本記事の関連研究:大規模言語モデルGPT-4、日本の医師国家試験に合格 国際研究チームが論文報告
専門分野における基盤モデルの可能性
人工知能の領域では、基盤モデルと呼ばれるAIモデルの形態が注目を集めています。基盤モデルとは、何らかの分野に特化して訓練されていない汎用的なモデルです。基盤モデルのうち特にGPT-4のような強力なものは、幅広いタスクにおいて高い性能を発揮しています。とはいえ、専門性の高い分野では、特化型モデルと比べて劣ると一般に考えられてきました。特に、医学のような高度な専門知識を要する分野では、その能力に疑問符がつけられています。
この疑問に対して、Microsoftの研究者たちは「実際はどうなのか?」と疑問を投げかけています。彼らは、特別なトレーニングを施さないGPT-4が、プロンプトの工夫だけでどこまで医学分野における問題解決能力を示すのかを検証することにしました。ある意味では前提を覆すかもしれない試みです。
従来の研究では、AIを特定の分野に適応(あるいは出力精度を大幅に向上)させるためには、その分野に関連する大量のデータでモデルを再トレーニングすることが必要だと考えられてきました。しかし、Microsoftの研究者たちは、特化型モデルの再トレーニングに代わるアプローチとして、プロンプトの工夫を用いることで、基盤モデルの隠れた能力を引き出す可能性に着目しました。
※専門モデルと比べてどちらが強力か?という煽りが注意を引くものの、基盤モデルの評価および能力強化におけるプロンプト手法の重要性に特に焦点が当てられています。
本記事の関連研究:医療AIの性能を検証する大規模プロジェクト、MITやハーバード、マイクロソフトなど始動
研究デザイン
この研究の核心部分の一つは、プロンプトフレームワーク「Medprompt」の構築にあります。GPT-4などの基盤モデルを特定の分野、今回は医学において高度な問題解決能力を発揮させることを目指しています。
Medpromptは主に三つの手法に基づいて構築されました。
- ダイナミック・フューショット
- 自己生成型思考チェーン (CoT)
- 選択肢シャッフル・アンサンブル
詳細は後述します。


そしてMedpromptをGPT-4に適用し、医学分野での問題解決能力を検証する実験が行われました。実験では、Medpromptの各構成要素がどのように基盤モデルの性能に寄与するかが分析されました。
本記事の関連研究:GPT-4をセラピストとして実行し、「認知の歪み」を診断させるためのフレームワーク『Diagnosis of Thought (DoT)』と実行プロンプト
「Medprompt」フレームワークの内容
「Medprompt」フレームワークでは、医学分野での問題解決において基盤モデルの能力を最大限に引き出すために、複数の手法が組み合わせられています。
要素1. ダイナミック・フューショット
最初の要素は「ダイナミック・フューショット」です。GPT-4に対して、
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。
















 PAGE TOP
PAGE TOP