
AI研究の最前線に立つDeepMindが新たな技術「RT-2」を開発しました。この技術は、ロボットが初めて見る環境で、初めて聞く指示に対しても適切な行動をとれるようにするものです。
参照論文情報
- タイトル:RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- 著者:Anthony Brohan, Noah Brown, Justice Carbajal et al.
- 所属:Google DeepMind
- URL:https://robotics-transformer2.github.io/assets/rt2.pdf
- GitHub:https://robotics-transformer2.github.io/
関連研究
- 仮想世界でサッカーを学んだロボットが実世界で上手にサッカーをプレイ DeepMindが研究報告
- DeepMindのタンパク質構造予測AI「AlphaFold」は進化を続けている
- 【DeepMind】AIの研究と「心理学の研究」の違いを語る
RT-2とは何か?
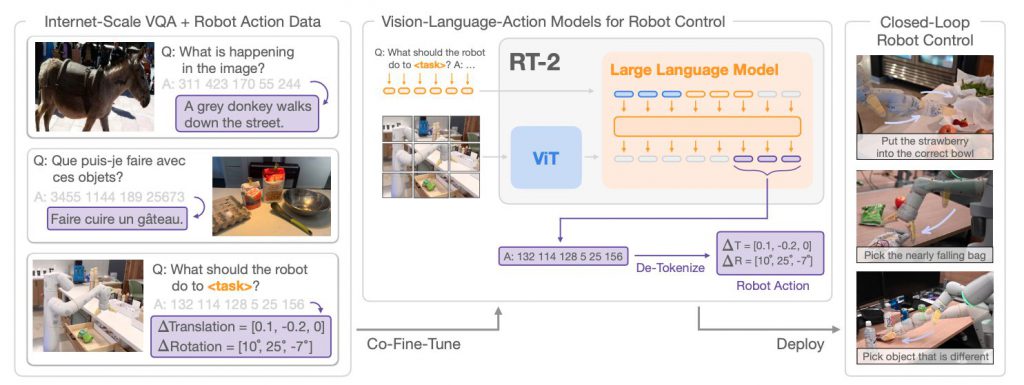
RT-2は、視覚と言語の情報を同時に処理し、それぞれの情報から得られる情報を統合して行動を生成する技術です。インターネット規模のデータで訓練した視覚言語モデルをロボットに組み込むことで、ロボットが人間が行うような複雑なタスクを自然かつ効率的に実行できるようになります。
視覚と言語の統合
RT-2の最大の特徴は、視覚と言語の情報を同時に処理する能力です。これにより、ロボットは視覚的な情報と言語的な指示を一度に理解し、それらを統合して適切な行動を生成することができます。
推論能力
RT-2は、ユーザーの指示をステップバイステップで推論する能力を備えています。例えば、「疲れた人に飲み物を運ぶ」というタスクにおいてエナジードリンクを選ぶなどの行動をとることができます。

技術的な特徴
RT-2は、一般化の強化と意味的な推論の実現を目指しています。以下では、RT-2の主な技術的な特徴について詳しく説明します。
ビジョン-ランゲージ-アクションモデル
RT-2は、ビジョン-ランゲージ-アクションモデル(VLAモデル)という新たなカテゴリのモデルを提案しています。これは、視覚と言語の両方を入力として取り、自然言語のトークンを生成するために訓練されたビジョン-ランゲージモデルを、ロボットのアクションを出力するように訓練するというアプローチを採用しています。
ロボットのアクションをテキストトークンとして表現し、それらを自然言語のトークンと同じようにモデルの訓練セットに直接組み込むことで、これを実現しています。このアプローチにより、ビジョン-ランゲージモデルは、ロボットの観測をアクションにマッピングする学習と、Webからの大規模な事前訓練の利点を享受する、一つのエンドツーエンド訓練モデルとして機能することが可能となります。
ロボットアクションの微調整
RT-2では、ビジョン-ランゲージモデルを制御するために、それらを訓練してアクションを出力するようにします。これを実現するために、アクションをモデルの出力のトークンとして表現します。これらのアクションのトークンは、言語のトークンと同じように扱われます。
アクションをテキストトークンに変換し、それらをカメラの観察とペアになったロボットの指示に「応答する」”マルチモーダルな文”を作成することで、ビジョン-ランゲージモデルを直接訓練して、指示に従うロボットのポリシーとして機能するようにします。
リアルタイム推論
現代のビジョン-ランゲージモデルのサイズは、数十から数百億のパラメータに達することがあります。このような大きなモデルをリアルタイムのロボット制御に直接使用することは現実的ではありません。そこで、RT-2では、モデルをマルチTPUクラウドサービスにデプロイし、ネットワーク経由でこのサービスをクエリすることで、リアルタイム制御を可能にしています。
このソリューションにより、適切な制御周波数を達成するとともに、同じクラウドサービスを使用して複数のロボットをサービスすることができます。最大のモデルである55BパラメータのRT-2-PaLI-X-55Bモデルは、1-3Hzの周波数で動作することができます。その小型版であるRT-2-PaLI-X-1.5Bモデルは、より高い周波数で動作することができます。
データ収集と訓練
RT-2の訓練データは、実世界のロボット操作から収集されます。これには、人間がロボットを遠隔操作する「テレオペレーション」のセッションが含まれます。これらのセッションでは、人間のオペレータがロボットに指示を出し、ロボットがそれに従って行動します。このプロセスを通じて、ロボットの観測、人間の指示、ロボットのアクションという3つの要素が結びつきます。
これらのデータは、ビジョン-ランゲージ-アクションモデルの訓練に使用されます。具体的には、ロボットの観測と人間の指示をモデルの入力とし、ロボットのアクションをモデルの出力とします。この訓練プロセスは、大量のデータと強力な計算リソースを必要とします。
RT-2は本当に優秀なのか?
RT-2の有効性を検証するために、研究者らは一連の実験を行いました。これらの実験は、RT-2が新たなオブジェクト、背景、環境に対してどの程度一般化できるか、そしてRT-2がどのような新たな能力を発揮できるかを評価することを目的としています。


