
世界のIT大手企業は「GAFA」と呼ばれており、FはFacebookを指しています。FacebookといえばSNSサービスのイメージが強いかもしれませんが、実はAI研究も精力的に実施しています。
今回は、「CVPR」という権威的な学会にて、Facebookが発表した論文を紹介します!

そもそもCVPRとは?
最初に、CVPRについて少し説明しておきます。
CVPRの正式名称は「Computer Vision and Pattern Recognition(コンピュータビジョンとパターン認識)」です。Compuer Visionというのはロボット(コンピュータ)の視覚を指します。画像処理、映像処理の技術分野全般を指すことが多いです。
近年ではComputer Vision分野でAI技術を使う事が当たり前になってきているため、CVPRはAI関連のトップ学会の一つとして認識されています。
「 Facebook Research 」の論文5つPICKUP
2020年度に開催されたCVPR 2020では、5865本の論文が投稿され、そのうちacceptされたのが1467本の論文でした。
この中から、Facebookの研究部門であるFacebook Researchが発表した5つの論文を紹介します。
1本目. Self-Supervised Learning of Pretext-Invariant Representations
2本目. 12-in-1: Multi-Task Vision and Language Representation Learning
3本目. DLWL: Improving Detection for Lowshot classes with Weakly Labelled data
4本目. PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
5本目. What Makes Training Multi-modal Classification Networks Hard?
1本目:自己教師あり学習の新たな可能性
現在、インターネットには大量のデータが存在しますが、それらのデータの教師データは用意するのに非常にコストがかかるという性質があります。そのような現状から、教師無し学習の一種である、Self-Supervised Learning、自己教師あり学習は、将来の人工知能のメインストリームになると考えられます。
タイトル:Self-Supervised Learning of Pretext-Invariant Representations(PDF)
著者:Ishan Misra, Laurens van der Maaten
課題設定のポイント
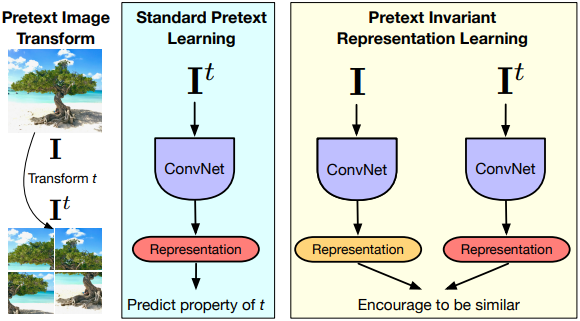
画像からの自己教師あり学習の目標は、意味的なアノテーションを必要としない前文タスクを介して、意味的に重要な画像表現を構築することです。多くの前文タスクは、画像の変換に共変な表現をもたらします。しかし、その結果、表現は変換と一致しなければならず、意味的な情報はあまり含まれていないかもしれません。
アプローチ・結果の面白さ
この論文では、代わりに、意味表現はそのような変換の下では不変であるべきであるという主張のもと、プレテキスト課題に基づいて不変表現を学習するPretextInvariant Representation Learning(PIRL)を開発しました。
著者らは、ジグソーパズルを解くという一般的に使われている前文課題を用いてPIRLを利用しました。その結果、PIRLは学習した画像表現の意味的品質を大幅に向上させることがわかりました。著者らのアプローチは、自己教師あり学習のためのいくつかの一般的なベンチマークを用いて、画像からの自己教師あり学習の新しい最先端を切り開くものです。教師なし学習であるにもかかわらず、PIRLは物体検出のための画像表現の学習において、教師ありの事前学習よりも優れた結果さえ出しました。
以上より、著者らの結果は、優れた不変性特性を持つ自己教師あり表現の可能性を示しています。
2本目:マルチタスクを可能にする
また記事の購読には、アカウント作成後の決済が必要です。
※ログイン/初回登録後、下記ボタンを押してください。
AIDBとは
プレミアム会員(記事の購読)について
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。










 PAGE TOP
PAGE TOP