
「3D×AIの最先端にキャッチアップしておきたい」
「トップ学会CVPR 2020の論文には関心があるが、数が多すぎてどれを読めばいいかわからない」
「画像認識技術を仕事で使うので注目度の高い論文に触れておきたい」
「そもそもCVPRって何?」
こんな方のために、アイブンよりサマリーをお届けします!

そもそもCVPRとは?
CVPRの正式名称は「Computer Vision and Pattern Recognition(コンピュータビジョンとパターン認識)」です。Compuer Visionというのはロボット(コンピュータ)の視覚を指します。画像処理、映像処理の技術分野全般を指すことが多いです。
そのComputer Visionの分野において最も権威ある学会の一つがこのCVPR。近年ではComputer Vision分野でDeep Learningを使う事が当たり前になってきているので、CVPRはDeep Learningに関するトップカンファレンスの一つだとも言われています。
3Dの論文5つPICKUP
CVPR 2020では、5865本の論文が投稿され、そのうちacceptされたのが1467本の論文でした。そのうち、3D関連の論文は142件でした。
この中から、特に興味深いおすすめの5本を紹介します。じっくり読む論文を選ぶ際のヒントにしていただけると幸いです。
1本目. Unsupervised Learning of Probably Symmetric Deformable 3D Objects From Images in the Wild
2本目. SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving
3本目. Footprints and Free Space From a Single Color Image
4本目. ActiveMoCap: Optimized Viewpoint Selection for Active Human Motion Capture
5本目. Through the Looking Glass: Neural 3D Reconstruction of Transparent Shapes
1本目:教師データなしで静止画から3Dデータを生成
まず初めに、CVPR 2020でBest Paper Awardに選ばれたこの論文から紹介します。
タイトル:Unsupervised Learning of Probably Symmetric Deformable 3D Objects From Images in the Wild(PDF)
著者:Shangzhe Wu, Christian Rupprecht, Andrea Vedaldi
機関・国:オックスフォード大学、イギリス
課題設定のポイント
教師データなしに、単一視点の静止画から3Dデータを生成します。
アプローチ・結果の面白さ
・入力画像を深度、アルベド(入射光と反射光の比)、視点、照明それぞれの因子に分解するオートエンコーダーを使用します。
・多くの対象の物体が左右対称な構造を持つということを前提にしています。この前提によって、深度やアルベドを反転させた状態でレンダリングを行っても同じ出力となるように学習をします。
・また、左右対称という制約は非常に強力なので、人間のヘアスタイルなど左右対称でないものも考慮に入れるため、同時に対称性確率マップを予測することで、物体の左右対称性の信頼度を推定し、損失関数に利用します。
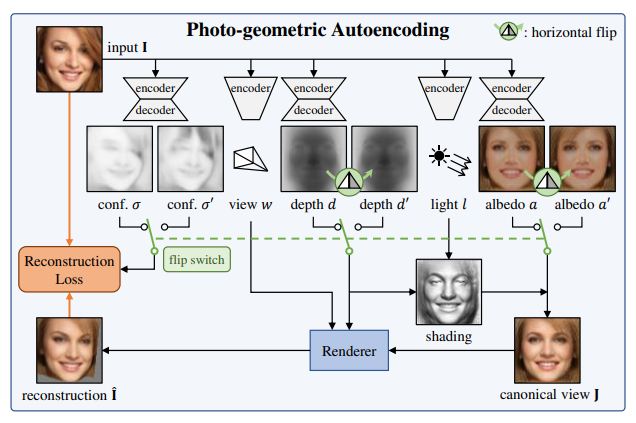
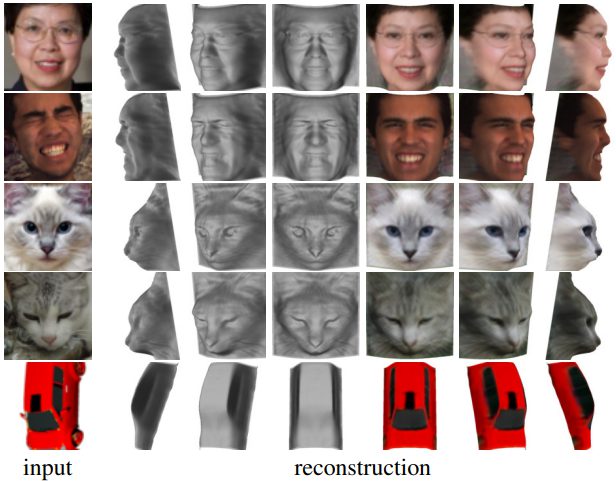
この手法によって、なんの教師データもなしに、単一視点の画像から人の顔、猫の顔、車の3D形状データを生成できるというのは驚くべきことです。
2本目:自動運転のためのデータ生成「SurfelGAN」
自動運転技術はコンピュータビジョン研究の1つの大きな成果だと言えます。
タイトル:SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving(PDF)
著者:Zhenpei Yang, Yuning Chai, Dragomir Anguelov, Yin Zhou, Pei Sun, Dumitru Erhan, Sean Rafferty, Henrik Kretzschmar
機関・国: テキサス大学オースティン校、アメリカ
課題設定のポイント
自動運転システムの開発は、シミュレーション環境の再現度に依存しています。現在では多くの場合UnrealやUnityなどのゲームエンジンが利用されますが、センサシミュレーションの設定は手動であり、現実との乖離も大きいです。
アプローチ・結果の面白さ
この論文では、現実世界での自律走行車によって収集された限られた量のLIDARやカメラのデータのみに基づいて、シミュレーション上でのセンサデータを生成するためのシンプルで効果的なアプローチSurfelGANを提案しています。
テクスチャマッピングされたサーフェル(3D形状の描画手法)を使用して、最初の車両のパスまたはパスのセットから効率的にシーンを再構築し、オブジェクトの3Dジオメトリと外観、およびシーンの条件に関する豊富な情報を保持します。次に、SurfelGANネットワークを活用して、シーン内の自動運転車と移動物体の新しい位置と向きのための現実的なカメラ画像を再構築します。
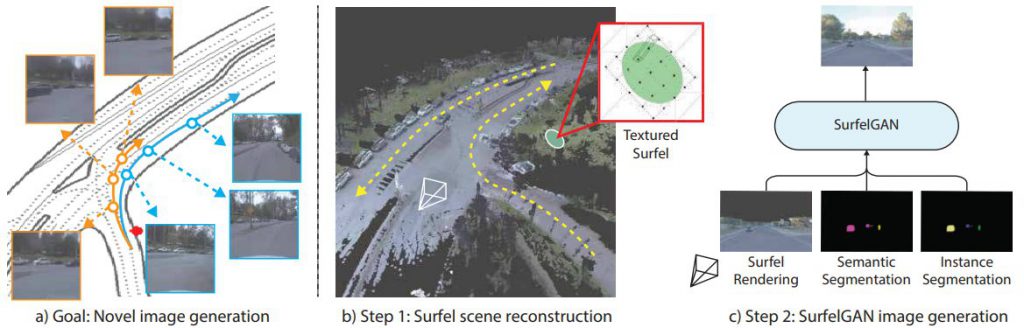
現実世界で取集された限られた量のセンサデータから自動運転のシミュレーションが生成できる点が、この研究の面白いポイントですね。
3本目:単一視点の画像から空間情報がわかる
続いて、画像の空間上をキャラクターが違和感なく歩き回るデモが印象的な論文を紹介します。

タイトル: Footprints and Free Space From a Single Color Image (PDF)
著者:Jamie Watson, Michael Firman, Aron Monszpart, Gabriel J. Brostow
機関・国:Niantic, Inc.、アメリカ
課題設定のポイント
1 枚のカラー画像からシーンの形状を理解することは、コンピュータビジョンの難しい課題です。ほとんどの既存手法では、カメラで見える表面の形状を予測することを目的としており、画像から推測できる空間全体の形状を推定することは行っていません。具体的には単一視点の画像から、移動可能な場所のセグメンテーション画像を出力します。
アプローチ・結果の面白さ
1枚のRGB画像を入力として、可視面と閉塞面の両方の横断可能な面の形状を予測するモデルを導入します。ステレオビデオシーケンスから、カメラのポーズ、フレームごとの深さ、意味的セグメンテーションを用いて学習します。トレーニングデータは、image-to-imageネットワークの教師データに使用されます。
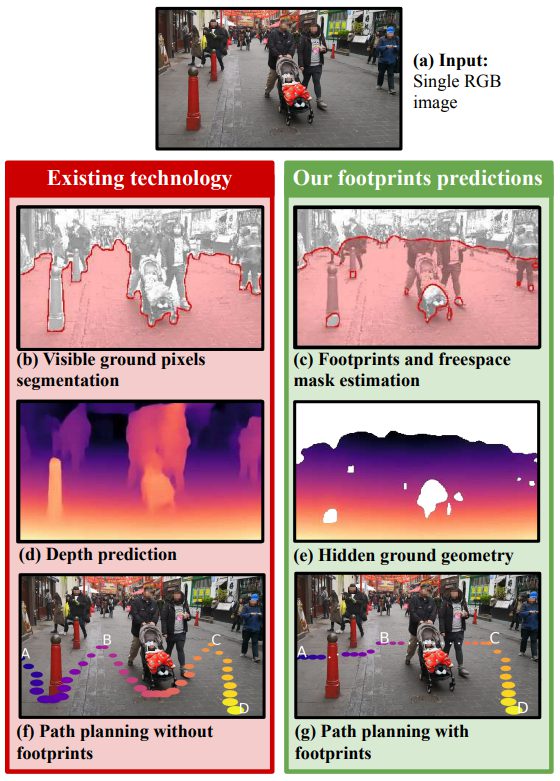
KITTI driving dataset、 the indoor Matterport dataset、および著者自身が何気なく撮影したステレオ映像からモデルを訓練し、評価して類似手法よりも高い精度が得られていることが確認できます。
デモ動画からわかるように、単一視点の画像から空間の情報を推測して、そこにオブジェクトを違和感なく表示できるのは見た目にもインパクトがあります。
4本目:ドローンによる人間の3D姿勢推定の進化系
個人的にドローンと3Dは相性が良さそうに感じますが、あまり研究が進んでないと感じましたので紹介してみます。
タイトル:ActiveMoCap: Optimized Viewpoint Selection for Active Human Motion Capture (PDF)
著者:Sena Kiciroglu, Helge Rhodin, Sudipta N. Sinha, Mathieu Salzmann, Pascal Fua
機関・国: スイス連邦工科大学ローザンヌ校、スイス
課題設定のポイント
単一視点による人間の姿勢推定の精度は、画像を撮影する視点に依存します。ドローンのように自由に動くカメラは視点を制御することができますが、精度が高くなるような位置に自動的にカメラを配置することはまだなされていません。
アプローチ・結果の面白さ
単一視点から2D姿勢推定と3D姿勢推定をして、次の時刻の3D姿勢を予測します。次に、予測した3D姿勢の姿勢推定の不確実性が最小になるように次の時刻の視点が決定されます。このようにしてドローンは最適な場所に移動しながら推定をする。
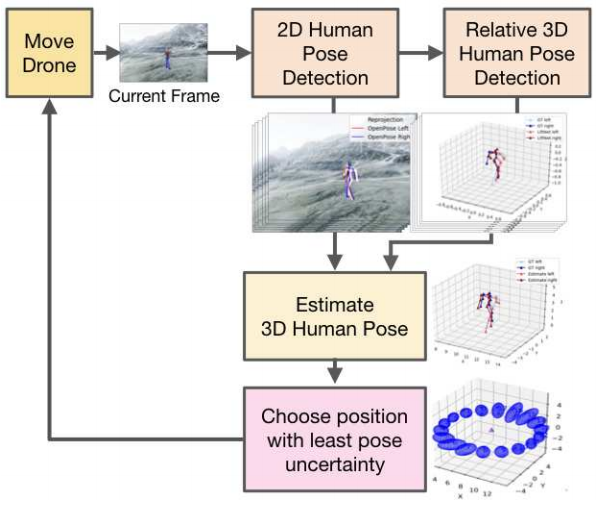
ドローンによる3D推定がメインではなく、3D推定をしやすいような視点の選択を提案している点がユニークですね。
5本目:透明な物体の3次元形状を再構成
最後に、単純に結果の見た目が良かった論文を紹介します。
タイトル: Through the Looking Glass: Neural 3D Reconstruction of Transparent Shapes(PDF)
著者:Zhengqin Li (co-first author), Yu-Ying Yeh (co-first author), Manmohan Chandraker
機関・国:カリフォルニア大学サンディエゴ校、アメリカ
課題設定のポイント
制約のない少数の自然画像を用いて透明な物体の三次元形状を復元することは、屈折と反射によって引き起こされる複雑な光路によって難しい問題となっています。著者らは論文で、既知の環境マップの下で、携帯電話のカメラで取得した少数の画像を用いて、透明な物体の3次元形状を回復する物理ベースのネットワークを提案しました。
アプローチ・結果の面白さ
ネットワークが局所的な計算によって複雑な光輸送をモデル化することを可能にする法線表現、屈折と反射をモデル化するレンダリング層、透明形状の法線絞り込みのために特別に設計されたコストボリューム、3D点群再構成のための予測法線に基づいた特徴マッピングを含むネットワークを提案しました。正解データの生成の難しさのため学習データ構築はCGによって構成されました。著者らの実験によると、5~12枚の画像で高品質の3D再構成が実現できることが示されています。

結果をみても、ぱっと見かなり正確にレンダリングできているように感じます。
以上、トマトがお送りしました。
今回は、「3D」という軸でCVPR 2020の論文を5つ紹介しました。引き続き、CVPR 2020の論文紹介を行っていきますので、今後もアイブンをぜひチェックしてください!

第1回:「3D」に関する論文5選
第2回:「GAN」に関する論文5選
第3回:「動画」に関する論文5選
第4回:「顔画像」に関する論文5選
第5回:「Facebook Research」が発表した論文5選
第6回:「Google」が発表した論文5選
第7回:【続】「動画」に関する論文5選
第8回:Twitterで話題になった一枚絵を3D化する技術
第9回:3Dのリアルな画像から「あらゆるテキストデータを抜きとるAI技術」発表
第10回:「3Dで」自画像を作るAI手法が発表された
■サポートのお願い
AIDBを便利だと思っていただけた方に、任意の金額でサポートしていただけますと幸いです。






 PAGE TOP
PAGE TOP